
Soul网关学习Http请求探险
回顾
在 Soul 请求处理概览概览这篇文章中,我们已经知晓了 Soul 针对于请求的处理入库在DefaultSoulPluginChain 的 excute,其中执行了一个插件链的模式来完成了请求的处理。
我们大体梳理了注入到plugins的插件,但是即使这样依然不能纵观全局,对此特地对 soul 插件所涉及的类进行了相关梳理,整体梳理结果如下图。
在梳理文章中可以看到核心类是SoulPlugin、PluginEnum、PluginDataHandler、MetaDataSubscriber,在梳理请求的相关文章中我们目前只需要重点关注 SoulPlugin 与 PluginEnum 类。
SoulPlugin 类我们已经有了一定的理解,那 PluginEnum 枚举类的主要作用是什么呢?
PluginEnum:插件的枚举类
| 属性 | 作用 |
|---|---|
| code | 插件的执行顺序 越小越先执行 |
| role | 角色 暂时未发现实际引用地址 |
| name | 插件名称 |
其实我们不难发现在DefaultSoulPluginChain 的 plugins的插件都是有固定的执行顺序的,那这个插件的执行顺序是在哪定义的呢?
最终可以追溯到SoulConfiguration类下
public SoulWebHandler soulWebHandler(final ObjectProvider<List<SoulPlugin>> plugins) {
//省略
final List<SoulPlugin> soulPlugins = pluginList.stream()
.sorted(Comparator.comparingInt(SoulPlugin::getOrder)).collect(Collectors.toList());
return new SoulWebHandler(soulPlugins);
}整理整个 PluginEnum 类相关引用,整理出如下表格,不难看出插件与插件之间的顺序关系
| 等级 | 作用 |
|---|---|
| 第一等级 | 只有 GlobalPlugin 全局插件 |
| 第二等级到第八等级 | 可以理解为在请求发起前的前置处理插件 |
| 第九等级到第十一等级 | 可以理解为针对调用方的方式所针对的不同调用处理 |
| 第十二等级 | 只有 MonitorPlugin 监控插件 |
| 第十三等级 | 是针对于各个调用方返回结果处理的 Response 相关插件 |
在刚才的回顾中我们已经明白 soul 处理请求的大体流程
- 1.GloBalPlugin 插件 进行全局的初始化
- 2.部分插件根据鉴权、限流、熔断等规则对请求进行处理
- 3.选择适合自己的调用方式进行拼装参数,发起调用。
- 4.进行监控
- 5.对调用的结果进行处理
请求流程梳理
以下演示代码截图来自于 soul-examples 下的 http demo,调用的接口地址为http://127.0.0.1:9195/http/test/findByUserId?userId=10
在DefaultSoulPluginChain 的 excute方法进行埋点,查看一次 http 请求调用经过了哪些类?
public Mono<Void> execute(final ServerWebExchange exchange) {
return Mono.defer(() -> {
if (this.index < plugins.size()) {
SoulPlugin plugin = plugins.get(this.index++);
Boolean skip = plugin.skip(exchange);
if (skip) {
System.out.println("跳过的插件为"+plugin.getClass().getName().replace("org.dromara.soul.plugin.",""));
return this.execute(exchange);
}
System.out.println("未跳过的插件为"+plugin.getClass().getName().replace("org.dromara.soul.plugin.",""));
return plugin.execute(exchange, this);
}
return Mono.empty();
});
}最终输出的未跳过的插件如下:
未跳过的插件为 global.GlobalPlugin
未跳过的插件为 sign.SignPlugin
未跳过的插件为 waf.WafPlugin
未跳过的插件为 ratelimiter.RateLimiterPlugin
未跳过的插件为 hystrix.HystrixPlugin
未跳过的插件为 resilience4j.Resilience4JPlugin
未跳过的插件为 divide.DividePlugin
未跳过的插件为 httpclient.WebClientPlugin
未跳过的插件为 alibaba.dubbo.param.BodyParamPlugin
未跳过的插件为 monitor.MonitorPlugin
未跳过的插件为 httpclient.response.WebClientResponsePlugin
这里有个小疑惑,为啥这个 alibaba.dubbo.param.BodyParamPlugin 插件会被执行,暂时忽略,后期跟踪。
我们发现一次针对于 http 请求的网关调用 所执行的插件的大体流程与我们猜想的处理流程一致。
目前我们只挑重点来讲,即GlobalPlugin、DividePlugin、WebClientPlugin、WebClientResponsePlugin。
发起 Debug 调用依次追踪上述四个插件的作用。
GlobalPlugin SoulContext 对象封装插件
GlobalPlugin 的插件的 excute 方法如下所示
public Mono<Void> execute(final ServerWebExchange exchange, final SoulPluginChain chain) {
final ServerHttpRequest request = exchange.getRequest();
final HttpHeaders headers = request.getHeaders();
final String upgrade = headers.getFirst("Upgrade");
SoulContext soulContext;
if (StringUtils.isBlank(upgrade) || !"websocket".equals(upgrade)) {
soulContext = builder.build(exchange);
} else {
final MultiValueMap<String, String> queryParams = request.getQueryParams();
soulContext = transformMap(queryParams);
}
exchange.getAttributes().put(Constants.CONTEXT, soulContext);
return chain.execute(exchange);
}不难看出 在 GlobalPlugin 的 excute 方法中主要目的就是封装一个SoulContext 对象,放入 exchange 中(exchange 对象是整个插件链上的共享对象,有一个插件执行完成后传递给下一个插件,本人理解的就是一个类似于 ThreadLocal 对象)。
那 SoulContext 对象中又包含哪些属性呢?
| 属性 | 含义 |
|---|---|
| module | 每种 RPCType 针对的值不同 http 调用时指代网关调用的前置地址 |
| method | 切割后的方法名(在 RpcType 为 http 时) |
| rpcType | RPC 调用类型有 Http、dubbo、sofa 等 |
| httpMethod | Http 调用的方式目前只支持 get、post |
| sign | 鉴权的相关属性目前不知道具体作用,可能与 SignPlugin 插件有关 |
| timestamp | 时间戳 |
| appKey | 鉴权的相关属性目前不知道具体作用,可能与 SignPlugin 插件有关 |
| path | 路径指代调用到 soul 网关的全路径(在 RpcType 为 http 时) |
| contextPath | 与 module 取值一致(在 RPCType 为 http 时) |
| realUrl | 与 method 的值一致(在 RpcType 为 http 时) |
| dubboParams | dubbo 的参数? |
| startDateTime | 开始时间怀疑与监控插件和统计指标模块有联用 |
在执行完 GlobalPlugin 插件后,最终封装完成的 SoulContext 对象如下所示。
其他 RPCType 的 SoulContext 的参数封装可以查看DefaultSoulContextBuilder 的 build方法进行追踪,由于本编文章主要追溯 http 调用,故在这里不在多余讨论。
DividePlugin 路由选择插件
在执行完成 GlobalPlugin 插件后,最终封装成了一个SoulContext 对象,并将其放在了ServerWebExchange中,供下游的调用链使用。
接下来让我们看一下DividePlugin 插件在整个链式调用过程中到底起了一个什么样的作用?
AbstractSoulPlugin
通过追溯源码得知DividePlugin 插件继承于 AbstractSoulPlugin 类,而 AbstractSoulPlugin 类实现了 SoulPlugin 接口。
那么AbstractSoulPlugin又做了哪些扩展呢?让我们梳理一下该类的方法。
| 方法名 | 作用 |
|---|---|
| excute | 实现于 SoulPlugin 接口,在 AbstractSoulPlugin 中起到一个模板方法的作用 |
| doexcute | 抽象方法 交由各个子类实现 |
| matchSelector | 匹配选择器 |
| filterSelector | 筛选选择器 |
| matchRule | 匹配规则 |
| filterRule | 筛选规则 |
| handleSelectorIsNull | 处理选择器为空情况 |
| handleRuleIsNull | 处理规则为空情况 |
| selectorLog | 选择器日志打印 |
| ruleLog | 规则日志打印 |
看一下excute方法的具体作用
public Mono<Void> execute(final ServerWebExchange exchange, final SoulPluginChain chain) {
String pluginName = named();
//获取对应插件
final PluginData pluginData = BaseDataCache.getInstance().obtainPluginData(pluginName);
//判断插件是否启用
if (pluginData != null && pluginData.getEnabled()) {
//获取插件下的所有选择器
final Collection<SelectorData> selectors = BaseDataCache.getInstance().obtainSelectorData(pluginName);
if (CollectionUtils.isEmpty(selectors)) {
return handleSelectorIsNull(pluginName, exchange, chain);
}
//匹配选择器
final SelectorData selectorData = matchSelector(exchange, selectors);
if (Objects.isNull(selectorData)) {
return handleSelectorIsNull(pluginName, exchange, chain);
}
//打印选择器日志
selectorLog(selectorData, pluginName);
final List<RuleData> rules = BaseDataCache.getInstance().obtainRuleData(selectorData.getId());
if (CollectionUtils.isEmpty(rules)) {
return handleRuleIsNull(pluginName, exchange, chain);
}
RuleData rule;
if (selectorData.getType() == SelectorTypeEnum.FULL_FLOW.getCode()) {
rule = rules.get(rules.size() - 1);
} else {
//匹配规则
rule = matchRule(exchange, rules);
}
if (Objects.isNull(rule)) {
return handleRu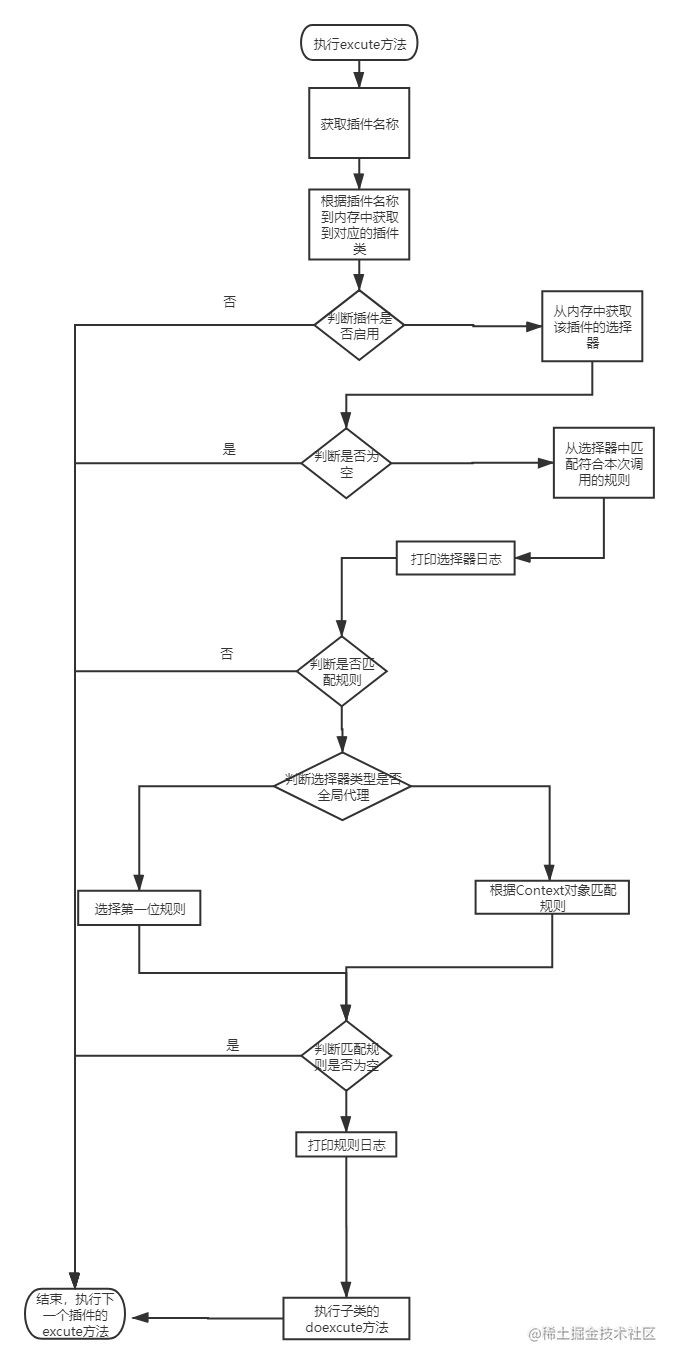leIsNull(pluginName, exchange, chain);
}
//打印规则日志
ruleLog(rule, pluginName);
//执行子类具体实现
return doExecute(exchange, chain, selectorData, rule);
}
return chain.execute(exchange);
}最终整理的流程图如下所示:
ps:在上述的流程图中并没有细化到具体的方法级别的处理。
但仍有几个点需要着重解释一下:
- 1.插件数据、选择器数据、规则数据的获取全部来自于BaseDataCache,该类是数据同步过程中最终会影响的类。
- 2.选择器的类型,在使用 SpringMvc 项目进行接口注册时,会有一个 isFull 的选项为 true 代表全局代理,在全局代理模式下只会注册一个选择器\规则(指代代理所有的接口),所以这里的对应处理为 rule.size()-1.
- 3.选择器和规则的选择,实际的处理要复杂的多,考虑到是介绍一次请求流程的大体逻辑,所以这里不展开阐述,有兴趣的可以查看MatchStrategy、AbstractMatchStrategy 及其相关实现类(后期会单独开一篇具体讲解),此处对应页面的如下:
梳理一下AbstractSoulPlugin 的 exeute 方法作用,经过上述流程图的引导,我们已经知晓该方法的作用是为了选取插件--->选取选择器--->选取规则,最后交由子类的doexcute方法。
接下来让我们看一下DividePlugin 的 doexcute方法具体做了哪些事。
DividePlugin
protected Mono<Void> doExecute(final ServerWebExchange exchange, final SoulPluginChain chain, final SelectorData selector, final RuleData rule) {
final SoulContext soulContext = exchange.getAttribute(Constants.CONTEXT);
assert soulContext != null;
//获取规则处理数据
final DivideRuleHandle ruleHandle = GsonUtils.getInstance().fromJson(rule.getHandle(), DivideRuleHandle.class);
//获取该选择器下的注入的地址
final List<DivideUpstream> upstreamList = UpstreamCacheManager.getInstance().findUpstreamListBySelectorId(selector.getId());
if (CollectionUtils.isEmpty(upstreamList)) {
log.error("divide upstream configuration error: {}", rule.toString());
Object error = SoulResultWrap.error(SoulResultEnum.CANNOT_FIND_URL.getCode(), SoulResultEnum.CANNOT_FIND_URL.getMsg(), null);
return WebFluxResultUtils.result(exchange, error);
}
final String ip = Objects.requireNonNull(exchange.getRequest().getRemoteAddress()).getAddress().getHostAddress();
//通过规则对应的负载均衡策略选择一个地址
DivideUpstream divideUpstream = LoadBalanceUtils.selector(upstreamList, ruleHandle.getLoadBalance(), ip);
if (Objects.isNull(divideUpstream)) {
log.error("divide has no upstream");
Object error = SoulResultWrap.error(SoulResultEnum.CANNOT_FIND_URL.getCode(), SoulResultEnum.CANNOT_FIND_URL.getMsg(), null);
return WebFluxResultUtils.result(exchange, error);
}
// set the http url
String domain = buildDomain(divideUpstream);
//拼装真实调用地址
String realURL = buildRealURL(domain, soulContext, exchange);
exchange.getAttributes().put(Constants.HTTP_URL, realURL);
//设置超时时间 及重试次数
exchange.getAttributes().put(Constants.HTTP_TIME_OUT, ruleHandle.getTimeout());
exchange.getAttributes().put(Constants.HTTP_RETRY, ruleHandle.getRetry());
return chain.execute(exchange);
}通过上述代码梳理完成后大体逻辑如下:
- 1.获取选择器对应的注册地址,对应页面数据如下
- 2.根据规则的 handle 字段获取负载均衡策略,并选择真实的调用地址(LoadBalanceUtils),重试次数和超时时间,对应页面数据如下。
- 3.将真实调用地址,超时时间,重试次数传递到ServerWebExchange中,供下游调用链使用。 debug 演示:
ps:在上述的主题逻辑中我们没有看到参数在哪里?那这个参数在哪封装的呢?答案在buildRealURL 方法中,是从exchange上下文中获取到的。
WebClientPlugin Http 请求调用插件
接下来让我们看看 Soul 如何发起的请求调用
public Mono<Void> execute(final ServerWebExchange exchange, final SoulPluginChain chain) {
final SoulContext soulContext = exchange.getAttribute(Constants.CONTEXT);
assert soulContext != null;
//获取真实地址
String urlPath = exchange.getAttribute(Constants.HTTP_URL);
if (StringUtils.isEmpty(urlPath)) {
Object error = SoulResultWrap.error(SoulResultEnum.CANNOT_FIND_URL.getCode(), SoulResultEnum.CANNOT_FIND_URL.getMsg(), null);
return WebFluxResultUtils.result(exchange, error);
}
//获取超时时间
long timeout = (long) Optional.ofNullable(exchange.getAttribute(Constants.HTTP_TIME_OUT)).orElse(3000L);
//获取重试次数
int retryTimes = (int) Optional.ofNullable(exchange.getAttribute(Constants.HTTP_RETRY)).orElse(0);
log.info("The request urlPath is {}, retryTimes is {}", urlPath, retryTimes);
HttpMethod method = HttpMethod.valueOf(exchange.getRequest().getMethodValue());
WebClient.RequestBodySpec requestBodySpec = webClient.method(method).uri(urlPath);
return handleRequestBody(requestBodySpec, exchange, timeout, retryTimes, chain);
}在 webClient 的excute方法中,主要做了三个事
- 1.将从 Divide 插件中放入 exchange 的属性取出来,调用的真实地址、超时时间、重试次数。
- 2.封装了一个RequestBodySpec对象(不认识这个响应式编程的东西)
- 3.调用了一个handleRequestBody方法
先认识handleRequestBody方法
private Mono<Void> handleRequestBody(final WebClient.RequestBodySpec requestBodySpec,
final ServerWebExchange exchange,
final long timeout,
final int retryTimes,
final SoulPluginChain chain) {
return requestBodySpec.headers(httpHeaders -> {
httpHeaders.addAll(exchange.getRequest().getHeaders());
httpHeaders.remove(HttpHeaders.HOST);
})
.contentType(buildMediaType(exchange))
.body(BodyInserters.fromDataBuffers(exchange.getRequest().getBody()))
.exchange()
//失败打印日志
.doOnError(e -> log.error(e.getMessage()))
//设置超时时间
.timeout(Duration.ofMillis(timeout))
//设置请求重试实际
.retryWhen(Retry.onlyIf(x -> x.exception() instanceof ConnectTimeoutException)
.retryMax(retryTimes)
.backoff(Backoff.exponential(Duration.ofMillis(200), Duration.ofSeconds(20), 2, true)))
//请求结束后对应的处理
.flatMap(e -> doNext(e, exchange, chain));
}在这个方法里,大体可以理解为
- exchange 中的请求头放到本次调用的请求头中
- 设置 contentType
- 设置超时时间
- 设置失败响应
- 设置重试的场景及重试次数
- 最终结果的处理。 在流程中需要还需要看一个doNext 方法
大体逻辑就是判断请求是否成功,将请求结果放入 exchange 中交给下游插件处理。
private Mono<Void> doNext(final ClientResponse res, final ServerWebExchange exchange, final SoulPluginChain chain) {
if (res.statusCode().is2xxSuccessful()) {
exchange.getAttributes().put(Constants.CLIENT_RESPONSE_RESULT_TYPE, ResultEnum.SUCCESS.getName());
} else {
exchange.getAttributes().put(Constants.CLIENT_RESPONSE_RESULT_TYPE, ResultEnum.ERROR.getName());
}
exchange.getAttributes().put(Constants.CLIENT_RESPONSE_ATTR, res);
return chain.execute(exchange);
}ps: 虽然并不懂响应式编程,但并不影响我们阅读代码。
WebClientResponsePlugin Http 结果处理插件
该实现的 excute 方法没有什么核心逻辑,就是判断请求状态码,根据状态码返回给前端不同的数据格式。
public Mono<Void> execute(final ServerWebExchange exchange, final SoulPluginChain chain) {
return chain.execute(exchange).then(Mono.defer(() -> {
ServerHttpResponse response = exchange.getResponse();
ClientResponse clientResponse = exchange.getAttribute(Constants.CLIENT_RESPONSE_ATTR);
if (Objects.isNull(clientResponse)
|| response.getStatusCode() == HttpStatus.BAD_GATEWAY
|| response.getStatusCode() == HttpStatus.INTERNAL_SERVER_ERROR) {
Object error = SoulResultWrap.error(SoulResultEnum.SERVICE_RESULT_ERROR.getCode(), SoulResultEnum.SERVICE_RESULT_ERROR.getMsg(), null);
return WebFluxResultUtils.result(exchange, error);
}
if (response.getStatusCode() == HttpStatus.GATEWAY_TIMEOUT) {
Object error = SoulResultWrap.error(SoulResultEnum.SERVICE_TIMEOUT.getCode(), SoulResultEnum.SERVICE_TIMEOUT.getMsg(), null);
return WebFluxResultUtils.result(exchange, error);
}
response.setStatusCode(clientResponse.statusCode());
response.getCookies().putAll(clientResponse.cookies());
response.getHeaders().putAll(clientResponse.headers().asHttpHeaders());
return response.writeWith(clientResponse.body(BodyExtractors.toDataBuffers()));
}));
}总结
到此为止,一个基于 Soul 网关发起的 Http 请求调用流程大体已经结束。
梳理 http 请求调用流程
- Global 插件封装 SoulContext 对象
- 前置插件处理熔断限流鉴权等操作。
- Divide 插件选择对应调用的真实地址,重试次数,超时时间。
- WebClient 插件发起真实的 Http 调用
- WebClientResponse 插件处理对应结果,返回前台。
基于 Http 调用的大体流程,我们可以大体猜测出基于别 RPC 调用的流程,就是替换发起请求的插件和返回结果处理的插件。
在上文中我们还提到了路由规则的选择LoadBalanceUtils,选择器和规则的处理MatchStrategy。
之后将会开启新篇章一步步揭开 RPC 泛化调用,路由选择,选择器、规则匹配的神秘面纱。