
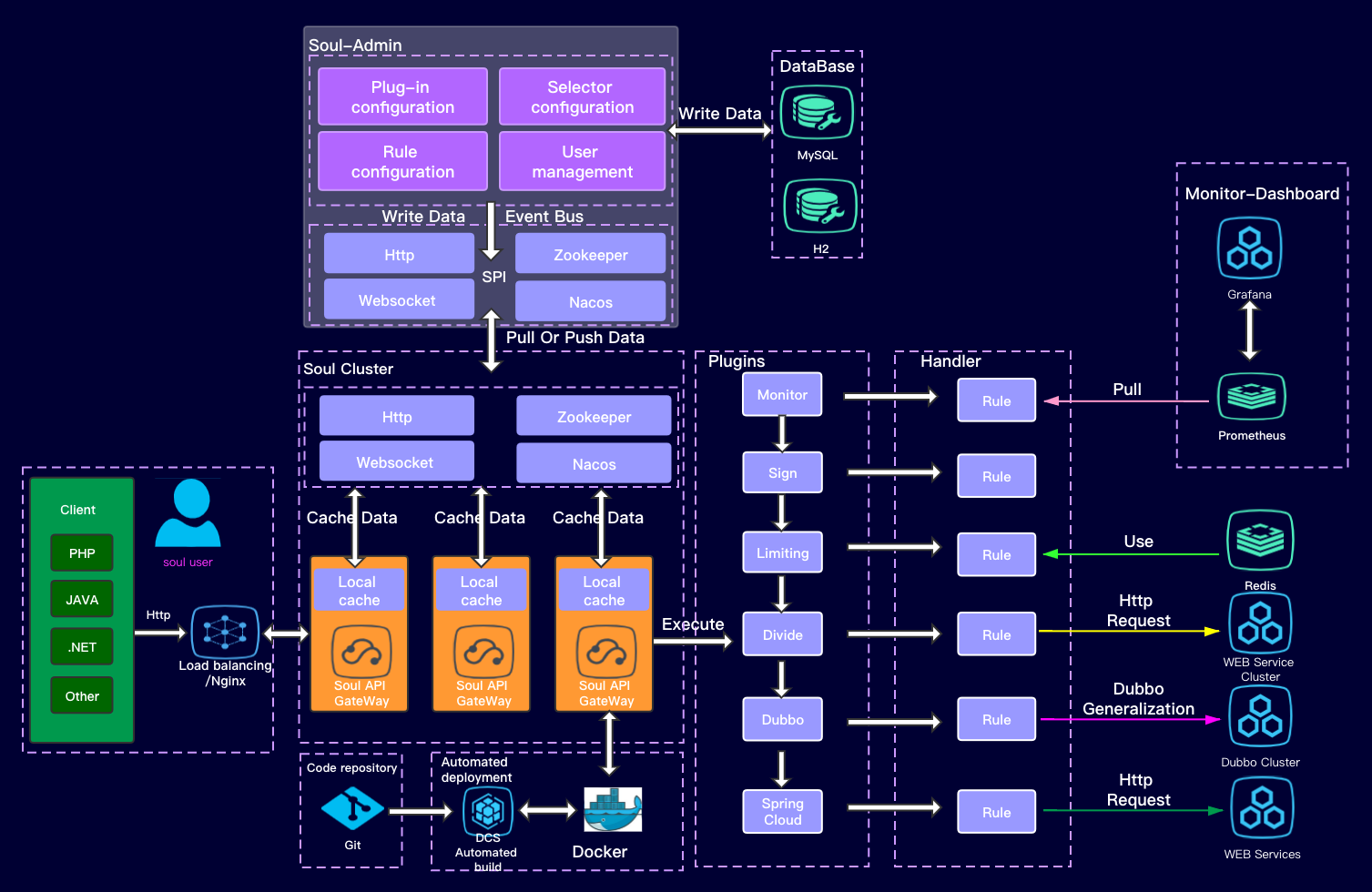
Soul Gateway learning plugin chain and load balancing analysis
Plug-in chain summary
Start with a class diagram:
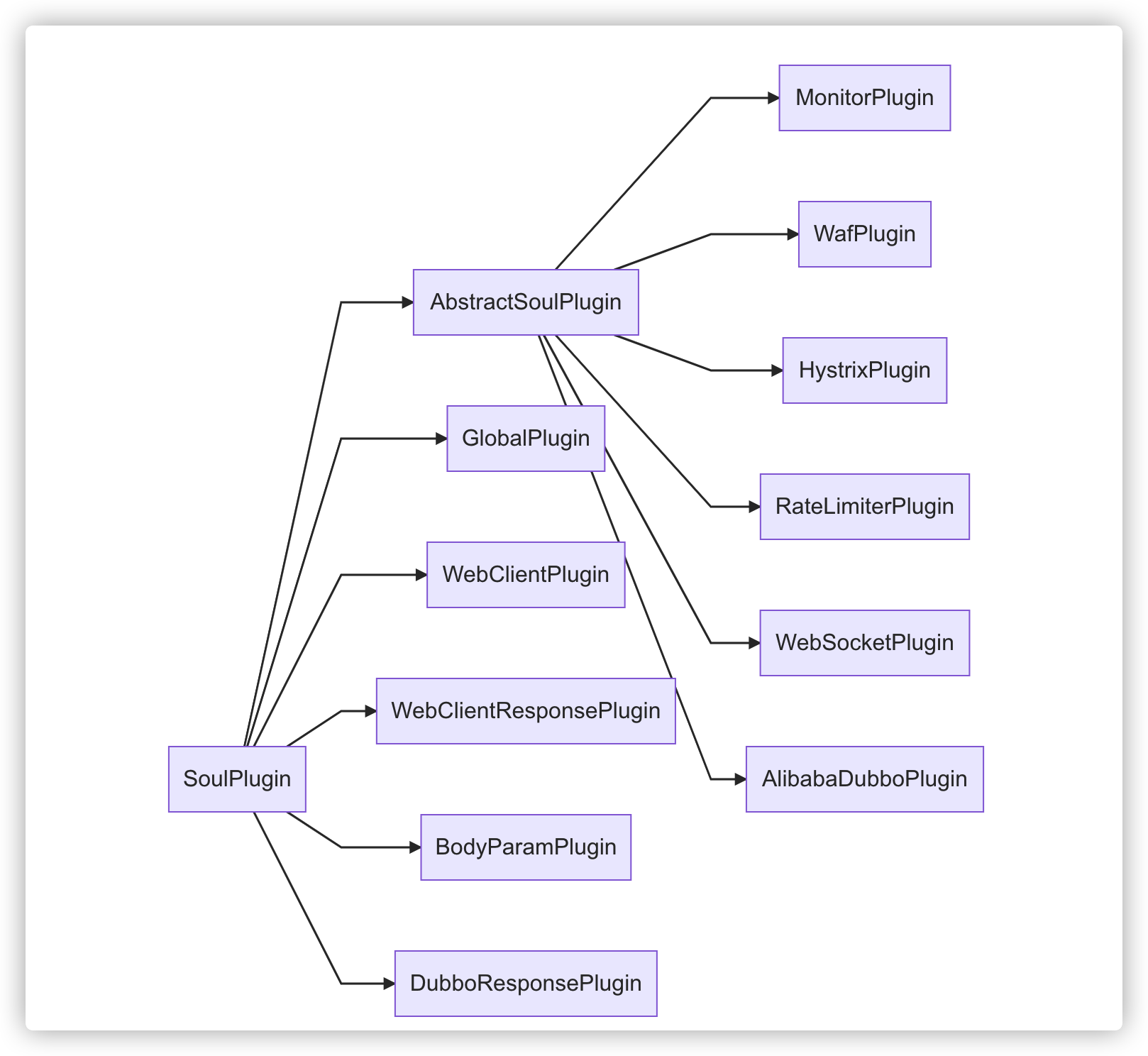
Two of the most basic plug-in classes are:
SoulPlugin: Defines the interface of the plug-in responsibility. The key method
execute()is called by the upper layer.skip()The method can cause some plug-ins to be skipped in some requests.AbstractPlugin: An abstract class that implements an interface
execute(), defines a common execution process, and uses the design pattern of the template method to providedoExecute()an abstract method for the implementation class to write its own logic.
AbstractSoulPlugin
Specific analysis of the execute() following AbstractSoulPlugin categories:
public Mono<Void> execute(final ServerWebExchange exchange, final SoulPluginChain chain) {
String pluginName = named();
final PluginData pluginData = BaseDataCache.getInstance().obtainPluginData(pluginName);
// If pluginData.getEnabled() is false, it will skip to the next plugin, only a few plugins will enter this condition (DividePlugin, AlibabaDubboPlugin, etc.)
if (pluginData != null && pluginData.getEnabled()) {
// Get all selectors on the plugin
final Collection<SelectorData> selectors = BaseDataCache.getInstance().obtainSelectorData(pluginName);
if (CollectionUtils.isEmpty(selectors)) {
return CheckUtils.checkSelector(pluginName, exchange, chain);
}
// Check whether the request path in the context matches the selector and get the only matching selector data
final SelectorData selectorData = matchSelector(exchange, selectors);
if (Objects.isNull(selectorData)) {
if (PluginEnum.WAF.getName().equals(pluginName)) {
return doExecute(exchange, chain, null, null);
}
return CheckUtils.checkSelector(pluginName, exchange, chain);
}
if (selectorData.getLoged()) {
log.info("{} selector success match , selector name :{}", pluginName, selectorData.getName());
}
// Gets the individual resource rules in the selector
final List<RuleData> rules = BaseDataCache.getInstance().obtainRuleData(selectorData.getId());
if (CollectionUtils.isEmpty(rules)) {
if (PluginEnum.WAF.getName().equals(pluginName)) {
return doExecute(exchange, chain, null, null);
}
return CheckUtils.checkRule(pluginName, exchange, chain);
}
RuleData rule;
if (selectorData.getType() == SelectorTypeEnum.FULL_FLOW.getCode()) {
rule = rules.get(rules.size() - 1);
} else {
// Match the path to obtain a unique rule
rule = matchRule(exchange, rules);
}
if (Objects.isNull(rule)) {
return CheckUtils.checkRule(pluginName, exchange, chain);
}
if (rule.getLoged()) {
log.info("{} rule success match ,rule name :{}", pluginName, rule.getName());
}
// Execute methods of subclasses
return doExecute(exchange, chain, selectorData, rule);
}
// Execute the next plug-in on the plug-in chain
return chain.execute(exchange);
}Through code analysis, some conclusions can be drawn:
- Execute () has two logics: one is the matching of the request path with the selector and the rule, which finally confirms a unique rule and calls the subclass doExecute (); The second is to execute the next plug-in in the plug-in chain.
- The execute () actually abstracts a set of rule matching logic, which is used by all the "forwarding type" plug-ins. Currently, I know the forwarding type plug-ins are
DividePlugin(HTTP request) andAlibabaDubboPlugin(dubbo request). Other types of plug-ins that do not override the execute () method will go directly to the next plug-in.
SoulPluginChain
Another point here is the formation and chain call of the plug-in chain. Let's analyze SoulPluginChain this part:

The SoulPluginChain interface also defines execute() methods for the caller to use, and its only subclass, DefaultSoulPluginChain, implements chained calls:
public Mono<Void> execute(final ServerWebExchange exchange) {
return Mono.defer(() -> {
// plugins contains all plugins loaded by the gateway
if (this.index < plugins.size()) {
// Each time the execute() method is called, the index index increases and is called to the next plug-in
SoulPlugin plugin = plugins.get(this.index++);
// Determine whether the current plug-in needs to be skipped based on the context
Boolean skip = plugin.skip(exchange);
if (skip) {
return this.execute(exchange);
} else {
return plugin.execute(exchange, this);
}
} else {
return Mono.empty();
}
});
}It's curious plugins to see where this list of plug-ins comes from. Here's an explanation. DefaultSoulPluginChain is a static inner class of SoulWebHandler. Is plugins an attribute in the Soul Web Handle:
public final class SoulWebHandler implements WebHandler {
private List<SoulPlugin> plugins;
public SoulWebHandler(final List<SoulPlugin> plugins) {
this.plugins = plugins;
// ...
}
@Override
public Mono<Void> handle(@NonNull final ServerWebExchange exchange) {
// ...
return new DefaultSoulPluginChain(plugins).execute(exchange).subscribeOn(scheduler)
.doOnSuccess(t -> startTimer.ifPresent(time -> MetricsTrackerFacade.getInstance().histogramObserveDuration(time)));
}
private static class DefaultSoulPluginChain implements SoulPluginChain {
}
}So where did the plugins SoulWeb Handler come from? You can continue to trace back to where its constructor was called:
@Configuration
public class SoulConfiguration {
@Bean("webHandler")
public SoulWebHandler soulWebHandler(final ObjectProvider<List<SoulPlugin>> plugins) {
List<SoulPlugin> pluginList = plugins.getIfAvailable(Collections::emptyList);
final List<SoulPlugin> soulPlugins = pluginList.stream()
.sorted(Comparator.comparingInt(SoulPlugin::getOrder)).collect(Collectors.toList());
soulPlugins.forEach(soulPlugin -> log.info("loader plugin:[{}] [{}]", soulPlugin.named(), soulPlugin.getClass().getName()));
return new SoulWebHandler(soulPlugins);
}
}It can be seen that the writing plugins is started by means of Spring Bean, that is, when the container starts, all plug-ins are loaded. Here, the entry parameter is used ObjectProvider to lazily load all beans of the SoulPlugin type (if none of them are used, no error will be reported) and inject them into the SoulWebHandler.
** There's a little hole to watch out for! **
All plug-ins, including DividePlugin, AlibabaDubboPlugin, etc., are configured by the XX PluginConfiguration class in their respective soul-spring-boot-starter-plugin-xx projects to register their own plug-ins as beans, similar to the following example:
@Configuration
public class DividePluginConfiguration {
@Bean
public SoulPlugin dividePlugin() {
return new DividePlugin();
}
}Therefore, in the gateway project soul-bootstrap, if you need to use a plug-in, you not only need to open the plug-in in the management background, but also need to confirm whether there is a dependency of the soul-spring-boot-starter-plugin-xx relevant plug-in in the following soul-bootstrap pom.xml, for example:
<dependency>
<groupId>org.dromara</groupId>
<artifactId>soul-spring-boot-starter-plugin-divide</artifactId>
<version>${project.version}</version>
</dependency>If you have a comment here or it doesn't exist, don't expect to see it on the plugin chain..
Plug-in project structure
Finally, briefly describe the functions of each plug-in project:
The first is the spring bean startup class project just mentioned, listing a general idea:
soul-spring-boot-starter-plugin-alibaba-dubbo soul-spring-boot-starter-plugin-apache-dubbo soul-spring-boot-starter-plugin-context-path soul-spring-boot-starter-plugin-divide soul-spring-boot-starter-plugin-global soul-spring-boot-starter-plugin-httpclient soul-spring-boot-starter-plugin-hystrix soul-spring-boot-starter-plugin-monitor soul-spring-boot-starter-plugin-ratelimiter soul-spring-boot-starter-plugin-resilience4j soul-spring-boot-starter-plugin-rewrite soul-spring-boot-starter-plugin-sentinel soul-spring-boot-starter-plugin-sign soul-spring-boot-starter-plugin-sofa soul-spring-boot-starter-plugin-springcloud soul-spring-boot-starter-plugin-tars soul-spring-boot-starter-plugin-wafTheir main functions have just been mentioned, registering their own SoulPlugin subclasses as spring beans, and registering spring beans to the PluginData Handler interface called in AbstractSoulPlugin. Provide its own implementation subclass, such as DividePluginDataHandler.
Specific plug-in class project:
soul-plugin-alibaba-dubbo soul-plugin-apache-dubbo soul-plugin-api soul-plugin-base soul-plugin-context-path soul-plugin-divide soul-plugin-global soul-plugin-httpclient soul-plugin-hystrix soul-plugin-monitor soul-plugin-ratelimiter soul-plugin-resilience4j soul-plugin-rewrite soul-plugin-sentinel soul-plugin-sign soul-plugin-sofa soul-plugin-springcloud soul-plugin-tars soul-plugin-wafTake the
soul-plugin-divideDividePlugin and DividePluginDataHandler mentioned just now as examples. And the project also has node information cache manager Upstream Cache Manager, load balancing strategy class LoadBalance and so on.
DividePlugin
The function of DividePlugin is to match Http requests. Since there are Http requests, there are naturally forwarding downstream and returning responses. So here we will analyze three plug-ins: DividePlugin, WebClientPlugin, WebClientResponsePlugin.
Let's start with that implementation in doExecute() DividePlugin, where I just keep the core point:
@Override
protected Mono<Void> doExecute(final ServerWebExchange exchange, final SoulPluginChain chain, final SelectorData selector, final RuleData rule) {
final SoulContext soulContext = exchange.getAttribute(Constants.CONTEXT);
final DivideRuleHandle ruleHandle = GsonUtils.getInstance().fromJson(rule.getHandle(), DivideRuleHandle.class);
// Get the cluster of service nodes in the cache by selector ID
final List<DivideUpstream> upstreamList = UpstreamCacheManager.getInstance().findUpstreamListBySelectorId(selector.getId());
// Call the load balancing method and pass in the policy type to get a unique node
DivideUpstream divideUpstream = LoadBalanceUtils.selector(upstreamList, ruleHandle.getLoadBalance(), ip);
// Get the real url of the node and put it in the exchange context
String domain = buildDomain(divideUpstream);
String realURL = buildRealURL(domain, soulContext, exchange);
exchange.getAttributes().put(Constants.HTTP_URL, realURL);
// Continue to call the next plug-in
return chain.execute(exchange);
}As you can see, after executing the DividePlugin doExecute() method, we already have the real path of the downstream service node in the ServerWeb Exchange context, and we just need to request it. But don't worry, the load balancing strategy here is also the key point, and then analyze.
Load balancing
How to execute the load balancing of Soul Gateway involves not only various strategies (hasn, random, polling), but also the concept of "weight score". The specific configuration of the management background is as follows:
待补,文章内部有报错
待补,文章内部有报错
待补,文章内部有报错
After showing the background configuration, let's take a look at the code implementation of each strategy.
Hash
public DivideUpstream doSelect(final List<DivideUpstream> upstreamList, final String ip) {
final ConcurrentSkipListMap<Long, DivideUpstream> treeMap = new ConcurrentSkipListMap<>();
for (DivideUpstream address : upstreamList) {
// Each node *VIRTUAL_NODE_NUM(default 5) to make the hash more uniform
for (int i = 0; i < VIRTUAL_NODE_NUM; i++) {
long addressHash = hash("SOUL-" + address.getUpstreamUrl() + "-HASH-" + i);
treeMap.put(addressHash, address);
}
}
// Obtain a hash value from the current ip address and compare treemap(ordered) to find a location greater than the hash value
long hash = hash(String.valueOf(ip));
SortedMap<Long, DivideUpstream> lastRing = treeMap.tailMap(hash);
// As long as the service node does not increase or decrease, the node obtained by the same ip address can remain unchanged
if (!lastRing.isEmpty()) {
return lastRing.get(lastRing.firstKey());
}
return treeMap.firstEntry().getValue();
}The load balancing of the hash algorithm does not use the concept of "weight score", that is to say, for each unknown IP, the probability of each node being accessed is the same. (Of course, multiple calls to the same IP will only access the same node.)
RandomLoadBalance
public DivideUpstream doSelect(final List<DivideUpstream> upstreamList, final String ip) {
// Total number
int length = upstreamList.size();
// Total weight
int totalWeight = 0;
// Whether the weights are the same
boolean sameWeight = true;
for (int i = 0; i < length; i++) {
int weight = upstreamList.get(i).getWeight();
// Cumulative total weight
totalWeight += weight;
if (sameWeight && i > 0
&& weight != upstreamList.get(i - 1).getWeight()) {
// Calculate whether the ownership weight is the same
sameWeight = false;
}
}
if (totalWeight > 0 && !sameWeight) {
// If the weights are not the same and the weights are greater than 0, random by the total weights
int offset = RANDOM.nextInt(totalWeight);
// and determine which segment the random value falls on
for (DivideUpstream divideUpstream : upstreamList) {
offset -= divideUpstream.getWeight();
if (offset < 0) {
return divideUpstream;
}
}
}
// Equally random if the weight is the same or if the weight is 0
return upstreamList.get(RANDOM.nextInt(length));
}When the rule is used random, all the node weights are accumulated and the number is obtained randomly, depending on the weight fragment of the node; If the score is 0 or the same, it is straightforward to randomize the cluster length.
RoundRobinLoadBalance
public DivideUpstream doSelect(final List<DivideUpstream> upstreamList, final String ip) {
String key = upstreamList.get(0).getUpstreamUrl();
ConcurrentMap<String, WeightedRoundRobin> map = methodWeightMap.get(key);
if (map == null) {
methodWeightMap.putIfAbsent(key, new ConcurrentHashMap<>(16));
map = methodWeightMap.get(key);
}
int totalWeight = 0;
long maxCurrent = Long.MIN_VALUE;
long now = System.currentTimeMillis();
DivideUpstream selectedInvoker = null;
WeightedRoundRobin selectedWRR = null;
for (DivideUpstream upstream : upstreamList) {
String rKey = upstream.getUpstreamUrl();
// Retrieves the node information in the cache
WeightedRoundRobin weightedRoundRobin = map.get(rKey);
int weight = upstream.getWeight();
if (weightedRoundRobin == null) {
weightedRoundRobin = new WeightedRoundRobin();
weightedRoundRobin.setWeight(weight);
map.putIfAbsent(rKey, weightedRoundRobin);
}
if (weight != weightedRoundRobin.getWeight()) {
weightedRoundRobin.setWeight(weight);
}
// Here is the first key: the score in the cache increases the weight score of the current node
long cur = weightedRoundRobin.increaseCurrent();
weightedRoundRobin.setLastUpdate(now);
// Select the node with a high cache score
if (cur > maxCurrent) {
maxCurrent = cur;
selectedInvoker = upstream;
selectedWRR = weightedRoundRobin;
}
totalWeight += weight;
}
if (!updateLock.get() && upstreamList.size() != map.size() && updateLock.compareAndSet(false, true)) {
try {
ConcurrentMap<String, WeightedRoundRobin> newMap = new ConcurrentHashMap<>(map);
newMap.entrySet().removeIf(item -> now - item.getValue().getLastUpdate() > recyclePeriod);
methodWeightMap.put(key, newMap);
} finally {
updateLock.set(false);
}
}
if (selectedInvoker != null) {
// Here is the second key: the score in the cache, reducing the total node weight score
selectedWRR.sel(totalWeight);
return selectedInvoker;
}
return upstreamList.get(0);
}This algorithm is a bit complicated. Let me explain the core aspect of calculating weights:
- Two nodes with a score of 2 and 100 respectively enter, and each of them is kept in the cache, with the score starting from 0.
- After the for loop, the scores of the two nodes in the cache will increase based on themselves. Assuming that the following steps are not performed, the cache will be 2 and 100 for the first time, 4 and 200 for the second time, and so on.
- The third key step is to select the node cache with the highest score and take "punishment" measures to reduce the cumulative score of all nodes, that is, 102.
According to the steps of this algorithm, nodes that have not been selected, as "growth rewards", will continue to increase on their own basis. The selected node, as a "penalty," reduces the sum of the weights of the other nodes.
It can be predicted that a node with a small weight will not be selected until a long time later. However, at that moment, it will be punished with great strength, which will lead to a long accumulation of strength once it returns to the pre-liberation period. For nodes with large weight scores, the penalty for being selected each time is very small. Even if the score is too low to be selected after many times, his reward score (itself) is particularly high, and one increase far surpasses other nodes.
WebClientPlugin
After the DividePlugin plug-in is called, the downstream service node path is determined, and then the Web ClientPlugin plug-in comes into play. It implements the SoulPlugin interface directly and implements the execute() methods (keeping only the core code):
public Mono<Void> execute(final ServerWebExchange exchange, final SoulPluginChain chain) {
String urlPath = exchange.getAttribute(Constants.HTTP_URL);
// Request type: Get request, orPost request, etc
HttpMethod method = HttpMethod.valueOf(exchange.getRequest().getMethodValue());
// Build a shell of the request object and inject the request type and URL
WebClient.RequestBodySpec requestBodySpec = webClient.method(method).uri(urlPath);
return handleRequestBody(requestBodySpec, exchange, timeout, chain);
}
private Mono<Void> handleRequestBody(final WebClient.RequestBodySpec requestBodySpec,
final ServerWebExchange exchange,
final long timeout,
final SoulPluginChain chain) {
return requestBodySpec.headers(httpHeaders -> {
// Add the request header in context... Later is also to add some attributes, do not go into details
httpHeaders.addAll(exchange.getRequest().getHeaders());
httpHeaders.remove(HttpHeaders.HOST);
})
.contentType(buildMediaType(exchange))
.body(BodyInserters.fromDataBuffers(exchange.getRequest().getBody()))
// Start asynchronous http calls to downstream services
.exchange()
.doOnError(e -> log.error(e.getMessage()))
.timeout(Duration.ofMillis(timeout))
// Callback receives the return value
.flatMap(e -> doNext(e, exchange, chain));
}
// Here is an asynchronous callback method that works in another thread
private Mono<Void> doNext(final ClientResponse res, final ServerWebExchange exchange, final SoulPluginChain chain) {
// ...
// Continue to complete the remaining plug-in chain calls
return chain.execute(exchange);
}Take a quick look at handleRequestBody() the implementation of this method in exchange(), here are the key Http calls:
class DefaultWebClient implements WebClient {
@Override
public Mono<ClientResponse> exchange() {
ClientRequest request = (this.inserter != null ?
initRequestBuilder().body(this.inserter).build() :
initRequestBuilder().build());
// Here is the critical call, which will go to spring-web-reactive
return Mono.defer(() -> exchangeFunction.exchange(request)
.checkpoint("Request to " + this.httpMethod.name() + " " + this.uri + " [DefaultWebClient]")
.switchIfEmpty(NO_HTTP_CLIENT_RESPONSE_ERROR));
}
}To sum up, the processing of Web ClientPlugin will call the downstream service asynchronously, wait for the response, and then execute the subsequent plug-in chain call in another thread.
WebClientResponseClient
Finally, the plug-in chain goes to the Web ClientResponseClient link to encapsulate the response information:
public Mono<Void> execute(final ServerWebExchange exchange, final SoulPluginChain chain) {
return chain.execute(exchange).then(Mono.defer(() -> {
// Gets the response information stored in the context
ServerHttpResponse response = exchange.getResponse();
ClientResponse clientResponse = exchange.getAttribute(Constants.CLIENT_RESPONSE_ATTR);
if (Objects.isNull(clientResponse)
|| response.getStatusCode() == HttpStatus.BAD_GATEWAY
|| response.getStatusCode() == HttpStatus.INTERNAL_SERVER_ERROR) {
Object error = SoulResultWarp.error(SoulResultEnum.SERVICE_RESULT_ERROR.getCode(), SoulResultEnum.SERVICE_RESULT_ERROR.getMsg(), null);
return WebFluxResultUtils.result(exchange, error);
} else if (response.getStatusCode() == HttpStatus.GATEWAY_TIMEOUT) {
Object error = SoulResultWarp.error(SoulResultEnum.SERVICE_TIMEOUT.getCode(), SoulResultEnum.SERVICE_TIMEOUT.getMsg(), null);
return WebFluxResultUtils.result(exchange, error);
}
// Various assembly
response.setStatusCode(clientResponse.statusCode());
response.getCookies().putAll(clientResponse.cookies());
response.getHeaders().putAll(clientResponse.headers().asHttpHeaders());
return response.writeWith(clientResponse.body(BodyExtractors.toDataBuffers()));
}));
}