
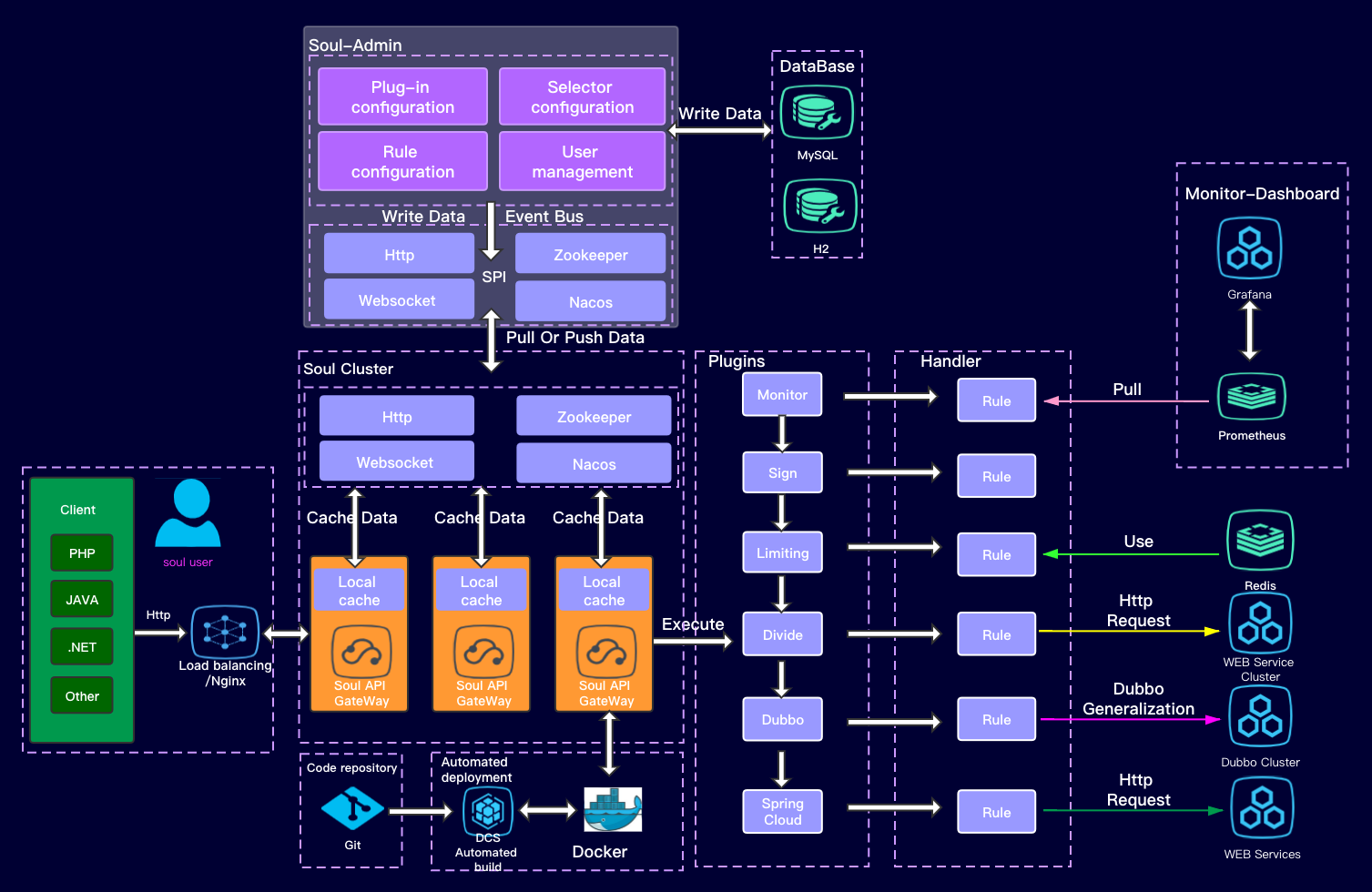
Soul网关学习SPI学习使用
SOUL 中 SPI 的使用
在之前分析 divide 插件的负载均衡策略时, 有看到过一行代码:
DivideUpstream divideUpstream = LoadBalanceUtils.selector(upstreamList, ruleHandle.getLoadBalance(), ip);当时很简单的略过了它的实现, 它的作用很容易分析, 调用一个看似工具类的方法, 传入多个节点组成的集群, 返回一个节点. 这是一个负载均衡器.
但是细节却非常多, 最重要的一点是使用 SPI 来选择具体的实现类. 看看这个方法的代码:
public class LoadBalanceUtils {
public static DivideUpstream selector(final List<DivideUpstream> upstreamList, final String algorithm, final String ip) {
// 调用自定义的 SPI 得到一个子类
LoadBalance loadBalance = ExtensionLoader.getExtensionLoader(LoadBalance.class).getJoin(algorithm);
return loadBalance.select(upstreamList, ip);
}
}后面的是调用具体子类的 select() 方法, 根据子类的不同实现, 最终会表现出各种形式. 目前的子类实现有:
- HashLoadBalance
- RandomLoadBalance
- RoundRobinLoadBalance
关键就在于 ExtensionLoader.getExtensionLoader(LoadBalance.class).getJoin(algorithm); 这行.
在研究它之前, 我们先不妨研究下 Java 提供的 SPI 机制.
Java SPI
<<高可用可伸缩微服务架构>> 第 3 章 Apache Dubbo 框架的原理与实现 中有这样的一句定义.
SPI 全称为 Service Provider Interface, 是 JDK 内置的一种服务提供发现功能, 一种动态替换发现的机制. 举个例子, 要想在运行时动态地给一个接口添加实现, 只需要添加一个实现即可.
书中也有个非常形象的脑图, 展示了 SPI 的使用:
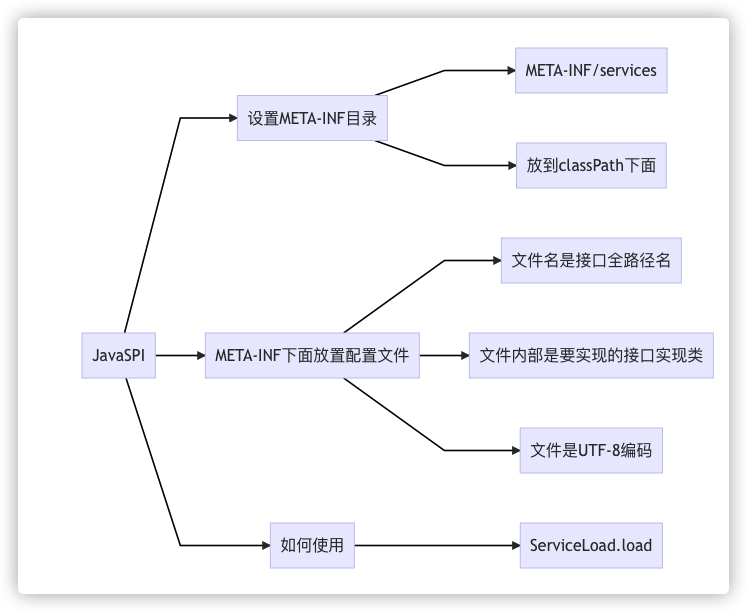
也就是说在我们代码中的实现里, 无需去写入一个 Factory 工厂, 用 MAP 去包装一些子类, 最终返回的类型是父接口. 只需要定义好资源文件, 让父接口与它的子类在文件中写明, 即可通过设置好的方式拿到所有定义的子类对象:
ServiceLoader<Interface> loaders = ServiceLoader.load(Interface.class)
for(Interface interface : loaders){
System.out.println(interface.toString());
}这种方式相比与普通的工厂模式, 肯定是更符合开闭原则, 新加入一个子类不用去修改工厂方法, 而是编辑资源文件.
从一个 Demo 开始
按照 SPI 的规范, 我建了一个 demo, 看看具体的实现效果
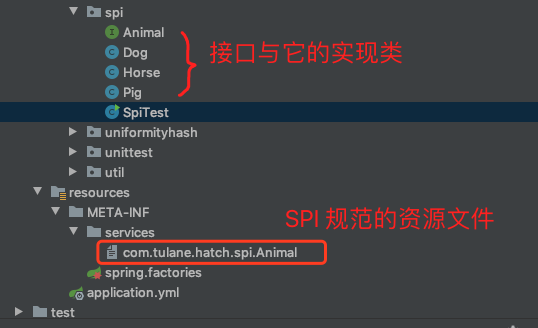
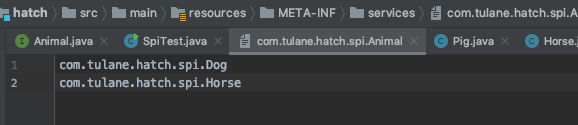
Animal 中定义一个 run() 方法, 而子类实现它.
public interface Animal {
void run();
}
public class Dog implements Animal {
@Override
public void run() {
System.out.println("狗在跑");
}
}
public class Horse implements Animal {
@Override
public void run() {
System.out.println("马在跑");
}
}使用 SPI 的加载类, 得到子类的执行结果:
private static void test() {
final ServiceLoader<Animal> load = ServiceLoader.load(Animal.class);
for (Animal animal : load) {
System.out.println(animal);
animal.run();
}
}
在调用后我们得到之前在资源文件中写入的实现类, 并成功调取它们各自的 run() 方法.
到这里我产生一个疑问, 是否每次调用 ServiceLoader.load(Animal.class) 返回的都是同一个对象? 如果是我猜测它是在启动时加载到缓存了, 如果不是, 可能就是在底层用了反射, 每次调用都有一定消耗. 我们看看下面的实验:
public static void main(String[] args) {
for (int i = 0; i < 2; i++) {
test();
System.out.println("----------");
}
}
private static void test() {
final ServiceLoader<Animal> load = ServiceLoader.load(Animal.class);
for (Animal animal : load) {
System.out.println(animal);
animal.run();
}
}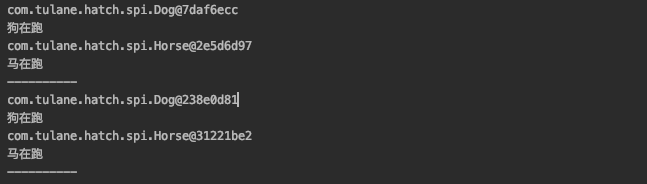
两次调用出现的对象却不一样, 不由让我替其性能揪心一下, 所以我们先分析下它的代码, 看看到底怎么实现.
SPI 的实现
找到 java.util,ServiceLoaders 这个类, 入眼最醒目的就是之前我们按照规范放置资源文件的目录
public final class ServiceLoader<S> implements Iterable<S> {
private static final String PREFIX = "META-INF/services/";
}在 debug PREFIX 属性的被调用处时, 发现 ServiceLoader.load 实际是使用懒加载的方式, 并没有在调用它的时候, 找寻到实际返回类, 而是在遍历时查找.
它的懒加载具体实现在如下代码:
public final class ServiceLoader<S> implements Iterable<S> {
public static <S> ServiceLoader<S> load(Class<S> service) {
// 获取当前的类加载器 (我们自己的通常是弟中弟 AppClassLoader )
ClassLoader cl = Thread.currentThread().getContextClassLoader();
return ServiceLoader.load(service, cl);
}
public static <S> ServiceLoader<S> load(Class<S> service, ClassLoader loader) {
// 调用构造器初始化对象 (说明每次调用都使用新的 ServiceLoader 对象)
return new ServiceLoader<>(service, loader);
}
private ServiceLoader(Class<S> svc, ClassLoader cl) {
service = Objects.requireNonNull(svc, "Service interface cannot be null");
loader = (cl == null) ? ClassLoader.getSystemClassLoader() : cl;
acc = (System.getSecurityManager() != null) ? AccessController.getContext() : null;
// 上面都是将信息放入对象实例属性中, 这行才是关键调用
reload();
}
public void reload() {
providers.clear();
// 创建懒加载迭代器, 传入关键的接口 Class 以及加载器
lookupIterator = new LazyIterator(service, loader);
}
}调用 ServiceLoader.load 后关键事情都没干, 仅仅是将接口 class 和加载器传给 LazyIterator 这个迭代器的实现类.
看到这可以猜测, 真正迭代调用返回的对象时, 肯定需要迭代器完成实现类的搜索和初始化, 而传参是 Class 信息和加载器, 实现类的初始化也明显会是反射了.
看下 LazyIterator 的实现方式, 先从其最开始会被调用到的 hasNext() 开始:
private class LazyIterator implements Iterator<S> {
public boolean hasNext() {
if (acc == null) {
return hasNextService();
} else {
// ...
}
}
private boolean hasNextService() {
if (nextName != null) {
return true;
}
if (configs == null) {
try {
String fullName = PREFIX + service.getName();
if (loader == null)
configs = ClassLoader.getSystemResources(fullName);
else
// 加载资源文件
configs = loader.getResources(fullName);
} catch (IOException x) {
fail(service, "Error locating configuration files", x);
}
}
while ((pending == null) || !pending.hasNext()) {
if (!configs.hasMoreElements()) {
return false;
}
// 解析出资源文件中写入的实现类类名
pending = parse(service, configs.nextElement());
}
// 获取一个类名
nextName = pending.next();
return true;
}
}
hasNext() 的调用可以获取到我们资源中的类名, 写入到实例属性 nextName 中, 并返回 true, 让迭代器可以进行 next() 的调用
public S next() {
if (acc == null) {
return nextService();
} else {
// ...
}
}
private S nextService() {
if (!hasNextService()) throw new NoSuchElementException();
String cn = nextName;
nextName = null;
Class<?> c = null;
try {
// 反射得到 Class 对象
c = Class.forName(cn, false, loader);
} catch (ClassNotFoundException x) {
fail(service, "Provider " + cn + " not found");
}
if (!service.isAssignableFrom(c)) {
fail(service, "Provider " + cn + " not a subtype");
}
try {
// 初始化对象, 并判断是否与接口符合
S p = service.cast(c.newInstance());
// 将初始化的对象放入hash缓存 (关键步骤)
providers.put(cn, p);
return p;
} catch (Throwable x) {
fail(service, "Provider " + cn + " could not be instantiated", x);
}
throw new Error(); // This cannot happen
}看到这里我们明白了, 在初始化后会将对象放入缓存中, key 就是接口 class 二次调用不会再有反射消耗.
那么之前我们在测试时的方式为什么会产生不同对象实例呢? 原因就是每次调用 ServiceLoader.load() 都会产生新的 ServiceLoader 对象. 我们将测试方法改进下:
public static void main(String[] args) {
// 复用 ServiceLoaders
final ServiceLoader<Animal> load = ServiceLoader.load(Animal.class);
for (int i = 0; i < 2; i++) {
test(load);
System.out.println("----------");
}
}
private static void test(ServiceLoader<Animal> load) {
for (Animal animal : load) {
System.out.println(animal);
animal.run();
}
}
Java SPI 思考
Java SPI 中我们还有很多的细节没有描述到, 但主流程就是这些. 我们之前的两个疑问点, 如何实现以及性能情况也可以得到解答:
- 如何实现: 通过 IO 流读取到资源文件, 反射加载对应路径并生成 Class 对象, 初始化后放入缓存中
- 性能情况: 首次迭代调用即会有反射调用, 但多次使用时, 只要保证是用同一个 ServiceLoader 对象, 即可避免多次反射, 因为会直接复用缓存中的对象.
写到这我有个非常疑惑的地方, 之前我觉得它和工厂方法很类似但比它有优势, 因为添加子类后仅需用改动资源文件不用变动工厂类.
但我尝试用 Java SPI 去真正实现时, 发现并不能达到这个效果, 一个重要的原因是, 资源文件中的各个实现类没有区分度, 我无法去筛选出某一个我需要的缓存在 ServiceLoaders 中的实现类.
那么它的使用场景在哪呢?
JDBC SPI 使用方式
经过查阅资料得知, 在 JDBC 中最关键的可插拔式驱动设计就是由 SPI 实现.
Mysql 驱动包 SPI
各个数据库连接包中关于 JDBC 方式实现, 都需要实现其 Driver 接口, 这块其实用的就是 SPI 的方式, 我们看看 mysql-connector-java.jar
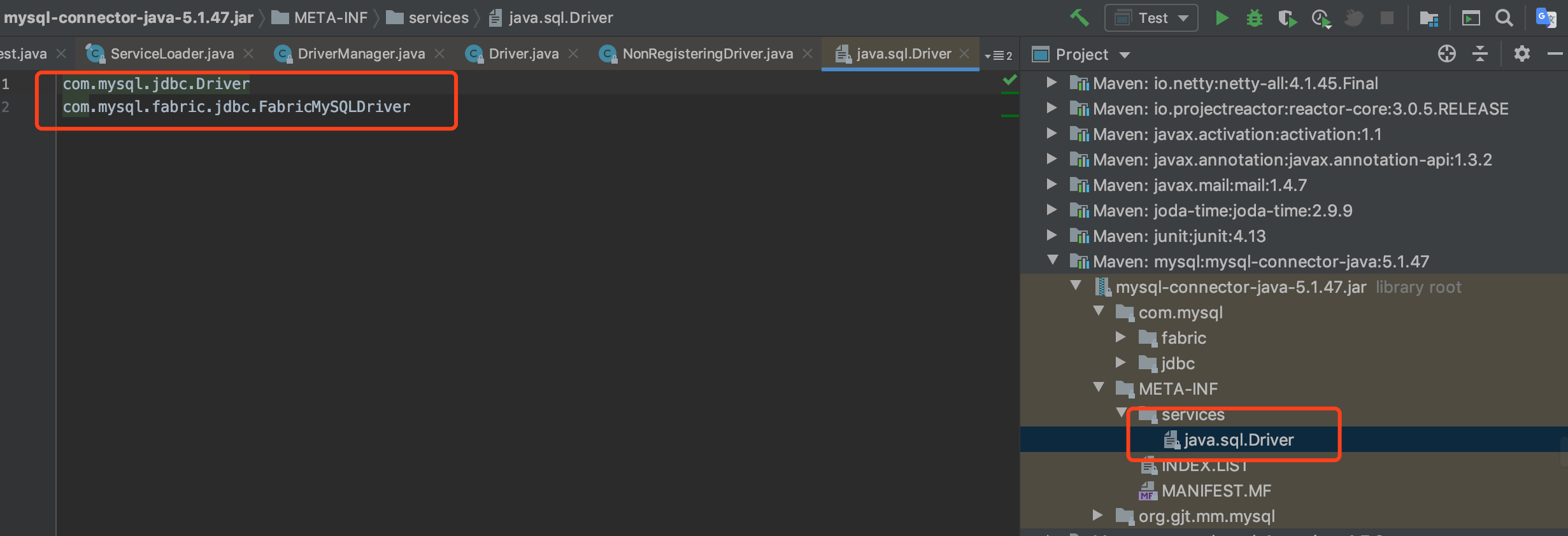
那么 JDK 中的 JDBC 相关类, 是如何实现这块的? 关键类就是 DriverManager
public class DriverManager {
static {
loadInitialDrivers();
}
private static void loadInitialDrivers() {
// ...
AccessController.doPrivileged(new PrivilegedAction<Void>() {
public Void run() {
// 这里就是 SPI 的实现, 迭代时实际会 Class.forName() 初始化实现类
ServiceLoader<Driver> loadedDrivers = ServiceLoader.load(Driver.class);
Iterator<Driver> driversIterator = loadedDrivers.iterator();
try{
while(driversIterator.hasNext()) {
driversIterator.next();
}
} catch(Throwable t) {
// Do nothing
}
return null;
}
});
// ...
}
}如果代码中调用到 DriverManager 的静态方法, 即会触发上面这些代码, 而这些代码的作用便是将 SPI 资源文件中 Driver 实现类全部初始化, 那么初始化实现类后又有什么作用呢? 接着看看 com.mysql.jdbc.Driver
public class Driver extends NonRegisteringDriver implements java.sql.Driver {
static {
try {
// 调用 DriverManager 的注册方法, 将此 Driver 实现类注册到 JDBC 的 Driver 管理器中
java.sql.DriverManager.registerDriver(new Driver());
} catch (SQLException E) {
throw new RuntimeException("Can't register driver!");
}
}
}DriverManager 的注册方法实现很简单, 即将入参放入静态变量作为全局缓存
public class DriverManager {
// 缓存 Driver 实现类
private final static CopyOnWriteArrayList<DriverInfo> registeredDrivers = new CopyOnWriteArrayList<>();
public static synchronized void registerDriver(java.sql.Driver driver) throws SQLException {
registerDriver(driver, null);
}
public static synchronized void registerDriver(java.sql.Driver driver, DriverAction da) throws SQLException {
if(driver != null) {
// 注册到变量中
registeredDrivers.addIfAbsent(new DriverInfo(driver, da));
} else {
throw new NullPointerException();
}
}
}筛选 Driver: 约定大于配置
正常使用时, 我们会直接用 DriverManager.getConnection(url, user, passwd) 获取到连接, 但这里就有疑问了, 我们在 DriverManager 中注册了多个 Driver, 为什么这里能确定一个唯一 Driver 呢?
先找到 DriverManager 的 getConnection() 方法:
public static Connection getConnection(String url, String user, String password) throws SQLException {
// ...
return (getConnection(url, info, Reflection.getCallerClass()));
}
private static Connection getConnection(
String url, java.util.Properties info, Class<?> caller) throws SQLException {
// ...
for(DriverInfo aDriver : registeredDrivers) {
// isDriverAllowed() 仅是通过 Class.forName() 初始化, 没有甄别作用
if(isDriverAllowed(aDriver.driver, callerCL)) {
try {
// 最关键的点在这行, 筛选工作其实在实现类自身的 connect() 方法中, 会根据传入的 url 筛选
Connection con = aDriver.driver.connect(url, info);
if (con != null) {
return (con);
}
} catch (SQLException ex) {
}
} else {
}
}
// ...
}看看最重要的 Mysql 的 Driver 中如何实现筛选 (Driver 继承自 NonRegisteringDriver)
public class NonRegisteringDriver implements java.sql.Driver {
private static final String URL_PREFIX = "jdbc:mysql://";
private static final String REPLICATION_URL_PREFIX = "jdbc:mysql:replication://";
private static final String MXJ_URL_PREFIX = "jdbc:mysql:mxj://";
public static final String LOADBALANCE_URL_PREFIX = "jdbc:mysql:loadbalance://";
public java.sql.Connection connect(String url, Properties info) throws SQLException {
// ...
// parseURL() 会匹配 url 是否符合其所在 Driver 的连接方式
// 这里就是采用"约定大于配置"的思想, 通过匹配路径头做筛选
if ((props = parseURL(url, info)) == null) {
return null;
}
// ...
}
public Properties parseURL(String url, Properties defaults) throws java.sql.SQLException {
// ...
// 如果 url 不匹配此 Driver 的路径则返回null, 最外层会继续尝试下个 Driver
if (!StringUtils.startsWithIgnoreCase(url, URL_PREFIX) && !StringUtils.startsWithIgnoreCase(url, MXJ_URL_PREFIX)
&& !StringUtils.startsWithIgnoreCase(url, LOADBALANCE_URL_PREFIX) && !StringUtils.startsWithIgnoreCase(url, REPLICATION_URL_PREFIX)) {
return null;
}
// ...
}
}总结 MySQL & JDBC
看到这里我想你已经了解 MySQL & JDBC 中关于 SPI 的实现方式了, 归纳几点
- JDBC 中的 DriverManager 会加载 SPI 资源文件, 将
java.sql.Driver的实现类全部初始化 - 其实现类初始化时, 会自主创建自身对象并注入到 DriverManager 中进行统一管理
- DriverManager 对于管理的 Driver 筛选方式是交由 Driver 实现类自身进行的, 它仅负责遍历并取出可用的 Driver
- Driver 实现类通过传入的数据库 url 头, 判断是否该返回自身. 如果判断为否则返回
null. JDBC 的 DriverManager 接收到null会继续下个 Driver 实现类的调用. - MySql 驱动实选方案是路径头匹配, 是一种 约定大于配置的思想
JDBC Demo
写完这些分析我们再来看如果实现个简单的 demo.
先分享个我以前写的方式
static {
try {
// 反射, 该类加载时会在静态块中, 向 DriverManager 注册 Driver
Class.forName("com.mysql.jdbc.Driver");
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
try (
final Connection conn = DriverManager.getConnection(url, user, passwd);
final Statement stmt = conn.createStatement();
final ResultSet rs = stmt.executeQuery("select count(1) from test")
) {
while (rs.next()) {
int count = rs.getInt("count(1)");
System.out.println(count);
}
} catch (Exception e) {
e.printStackTrace();
}
}虽然这样可以使用, 但不觉得有多余的代码吗? 看看我新写的方式
public static void main(String[] args) throws ClassNotFoundException {
try (
final Connection conn = DriverManager.getConnection(url, user, passwd);
final Statement stmt = conn.createStatement();
final ResultSet rs = stmt.executeQuery("select count(1) from test")
) {
while (rs.next()) {
int count = rs.getInt("count(1)");
System.out.println(count);
}
} catch (Exception e) {
e.printStackTrace();
}
}仅仅需要这些简单的代码即可, DriverManager.getConnection() 被调用时 DriverManager 会自动加载 SPI 中的实现类, 不需要我们再去 Class.forName() 手动调用 java.mysql.Driver 的初始化.
看到这里我想你依然明白 SPI 最最重要的作用了. 无需显式的写出接口对应的实现类
那么我们还有个在 "Java SPI 思考" 中的问题也解开了. **如何区分出 SPI 中要使用的实现类呢? 让实现类自己判定即可, 外层调用仅需迭代所有. **
SOUL SPI 实现
Java 中 SPI 的使用方式我们已经掰开来了解透彻了, 而 Soul 中的 SPI 是自己设计的, 采用 Dubbo 中 SPI 的设计思想. 在 org.dromara.soul.spi.SPI 注释类上可以看到相关注释.
/**
* SPI Extend the processing.
* All spi system reference the apache implementation of
* https://github.com/apache/dubbo/blob/master/dubbo-common/src/main/java/org/apache/dubbo/common/extension.
*/Java SPI 缺陷
在上两个模块中分析 Java SPI 使用时, 发现了些缺点:
- 如果使用 ServiceLoader 不当, 没有正确利用到它的缓存机制, 会导致每次获取具体实现类都要反射出类对象以及初始化实例对象, 性能完蛋不说, 每次得到的对象都不一样可能会引发程序问题.
- 即每次找寻具体实现类都要迭代一遍才行, 虽然子类少的使用没什么影响, 但这种方式还是很傻. 另外参考 MySQL 驱动中 JDBC 的实现, 还需要自行设计一套比较复杂的筛选机制.
那么 Soul SPI 的实现, 是如何解决这两个问题的? 关键就在接下来的两个子模块中
- 优化的 ExtensionLoader
- 增强型 getJoin()
优化的 ExtensionLoader
先来看 SPI 实现项目的全貌, 项目为 soul-spi:
其中最核心的类就是 ExtensionLoader, 可以说是 Soul 版的 ServiceLoader, 它也定义了 SPI 资源文件的路径位置
public final class ExtensionLoader<T> {
private static final String SOUL_DIRECTORY = "META-INF/soul/";
}通过检查它各个方法的调用处, 我们找到入口方法 getExtensionLoader()
public final class ExtensionLoader<T> {
private static final Map<Class<?>, ExtensionLoader<?>> LOADERS = new ConcurrentHashMap<>();
public static <T> ExtensionLoader<T> getExtensionLoader(final Class<T> clazz) {
// ...
// 根据加载类对象取出缓存中数据, 如果没有则新建 ExtensionLoader 对象并放入缓存
ExtensionLoader<T> extensionLoader = (ExtensionLoader<T>) LOADERS.get(clazz);
if (extensionLoader != null) {
return extensionLoader;
}
LOADERS.putIfAbsent(clazz, new ExtensionLoader<>(clazz));
return (ExtensionLoader<T>) LOADERS.get(clazz);
}
}这个方法的作用其实就像是 ServiceLoader 的 load() 方法, 会返回一个 ServiceLoader 对象.
只是 Soul 中的实现改了种方式, 将 ExtensionLoader 对象缓存起来, 这样 二次调用时传入相同 Class 对象也会返回同样的 ExtensionLoader, 避免了 ServiceLoader 使用时不理解其机制导致没有用到它的缓存, 每次迭代都去反射初始化所有实现类
增强型搜索 getJoin()
再来看看 ExtensionLoader 的 getJoin() 方法, 我将它理解为 更优的 ServiceLoader 迭代器版实现. 它同样是做了两件 ServiceLoader 迭代时做过的事情:
初始化 SPI 中的实现类
将实现类缓存 -> 缓存为 Key-Value 形式的 Map 集合
基于 K-V 缓存模式, 它还做了一件我最期待的改造:
- 时间复杂度
O(1)的直接匹配实现类方式
多层缓存
ExtensionLoader 之所以能做到这种增强型搜索, 无需每次都迭代所有, 是依靠三种不同类型的缓存.
这三种缓存我将它分为二层, 它们各有不同用途, 总览如下:
// 一层缓存
private final Map<String, Holder<Object>> cachedInstances = new ConcurrentHashMap<>();
// 二层缓存之一
private final Holder<Map<String, Class<?>>> cachedClasses = new Holder<>();
// 二层缓存之一
private final Map<Class<?>, Object> joinInstances = new ConcurrentHashMap<>();第一层缓存: cachedInstances
首先是第一层缓存, 它是我们搜索接口的具体实现类时最先接触到的, 如果命中它则直接可以得到实现类的对象
private final Map<String, Holder<Object>> cachedInstances = new ConcurrentHashMap<>();它的 key 其实就是 Soul SPI 资源文件中我们配置的信息, 比如 Divide 插件的负载均衡实现类的资源文件
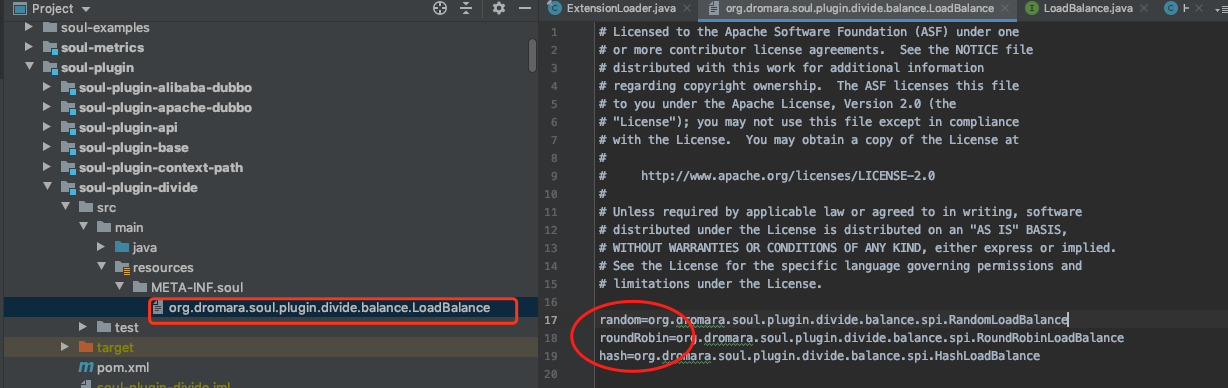
而它的 value 则是 Holder 对象, 其中存有实现类的对象. 调用 getJoin() 时传入标识 (比如 random) 获得实现类对象.
public T getJoin(final String name) {
// ...
Holder<Object> objectHolder = cachedInstances.get(name);
Object value = objectHolder.getValue();
// ...
return (T) value;
}第二层缓存之: cachedClasses
cachedClasses 存放的是 标识(random) 与 类对象 的映射
private final Holder<Map<String, Class<?>>> cachedClasses = new Holder<>();cachedClasses 缓存的信息如何填充的呢? 是直接触发到检索 SPI 资源文件, 然后解析成 cachedClasses 缓存. 具体方法在 loadResources() 中
private void loadResources(final Map<String, Class<?>> classes, final URL url) throws IOException {
Properties properties = new Properties();
// 解析资源文件
properties.load(inputStream);
properties.forEach((name, classPath) -> {
// 读出 K-V 结构并组装成 classes, 外层调用会包装到 cachedClasses
loadClass(classes, name, classPath);
});
}第二层缓存之: joinInstances
joinInstances 缓存存放的是 类对象与对象实例 的映射
private final Map<Class<?>, Object> joinInstances = new ConcurrentHashMap<>();这一层缓存会借助第二层缓存, 得到对应标识(random) 的类对象, 并通过类对象初始化实例, 缓存到自身中. 对应实现方法为 createExtension()
private T createExtension(final String name) {
Class<?> aClass = getExtensionClasses().get(name);
Object o = joinInstances.get(aClass);
if (o == null) {
joinInstances.putIfAbsent(aClass, aClass.newInstance());
}
return (T) o;
}缓存小结
通过 ExtensionLoader 加载某个接口的实现类时, 缓存调用流程图如下:
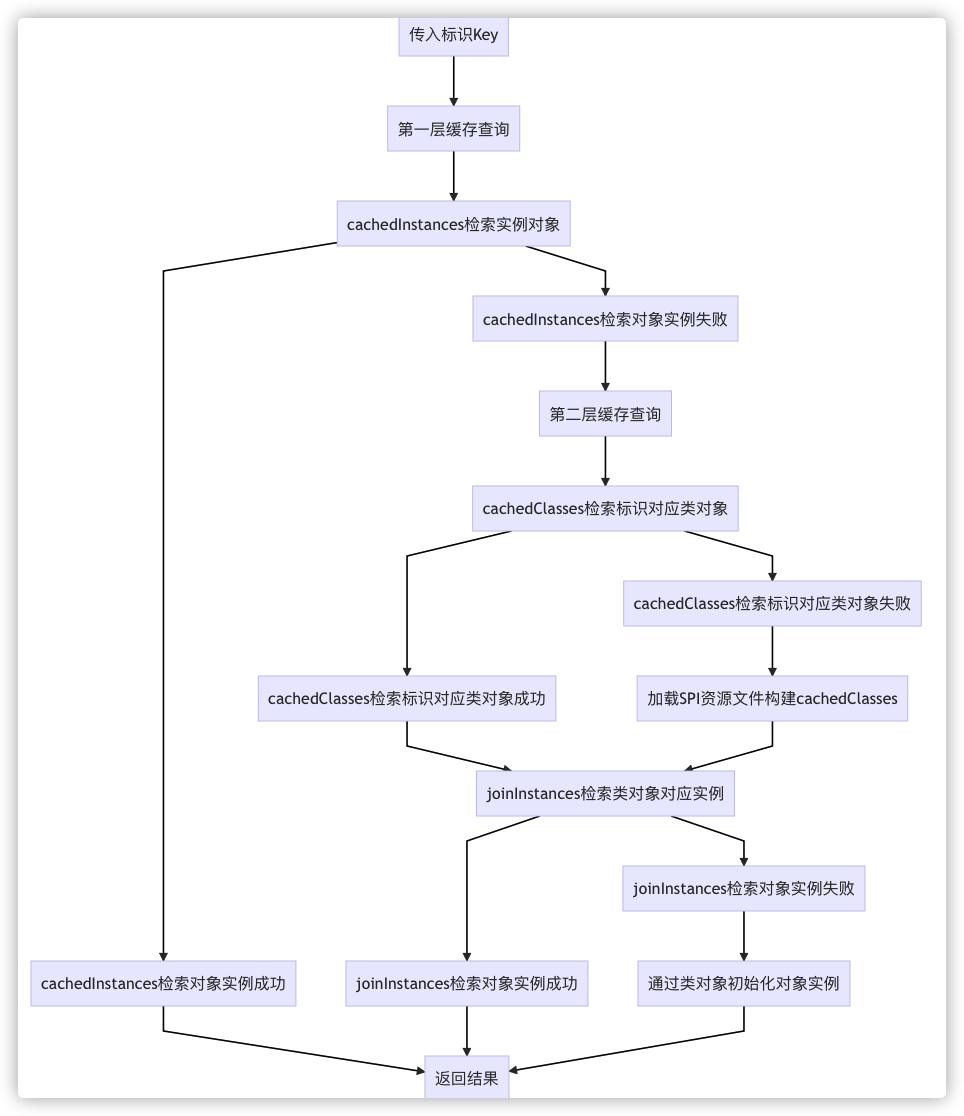
详细源码分析 (可跳过)
// name 理解为标识, 用于甄别 SPI 文件中, 想要获取的某个实现类
public T getJoin(final String name) {
// ...
// cachedInstances 缓存所有 Holder 对象. Holder 对象的 value 属性存放具体实现类
// 我将 cachedInstances 理解为第一层缓存, 命中则直接返回要找的类
Holder<Object> objectHolder = cachedInstances.get(name);
if (objectHolder == null) {
cachedInstances.putIfAbsent(name, new Holder<>());
objectHolder = cachedInstances.get(name);
}
Object value = objectHolder.getValue();
// 双重锁, 如果没有命中则调用 createExtension()
if (value == null) {
synchronized (cachedInstances) {
value = objectHolder.getValue();
if (value == null) {
value = createExtension(name);
objectHolder.setValue(value);
}
}
}
return (T) value;
}private T createExtension(final String name) {
// 关键代码, 搜索标识对应的类对象
Class<?> aClass = getExtensionClasses().get(name);
if (aClass == null) {
throw new IllegalArgumentException("name is error");
}
// joinInstances 理解为第二层缓存, K-V 存放类对象与其初始化对象
Object o = joinInstances.get(aClass);
if (o == null) {
try {
joinInstances.putIfAbsent(aClass, aClass.newInstance());
o = joinInstances.get(aClass);
} catch (InstantiationException | IllegalAccessException e) {
// ...
}
}
return (T) o;
}public Map<String, Class<?>> getExtensionClasses() {
// cachedClasses 为第三层缓存, 存放标识与类对象映射
Map<String, Class<?>> classes = cachedClasses.getValue();
if (classes == null) {
synchronized (cachedClasses) {
classes = cachedClasses.getValue();
if (classes == null) {
// 构造 classes 缓存, classes 的 K-V 结构为 标识-类对象
classes = loadExtensionClass();
cachedClasses.setValue(classes);
}
}
}
return classes;
}private Map<String, Class<?>> loadExtensionClass() {
// 拿到接口的 SPI 注解
SPI annotation = clazz.getAnnotation(SPI.class);
if (annotation != null) {
String value = annotation.value();
if (StringUtils.isNotBlank(value)) {
cachedDefaultName = value;
}
}
// 构造 classes 缓存, classes 的 K-V 结构为 标识-类对象
Map<String, Class<?>> classes = new HashMap<>(16);
loadDirectory(classes);
return classes;
}private void loadDirectory(final Map<String, Class<?>> classes) {
String fileName = SOUL_DIRECTORY + clazz.getName();
try {
ClassLoader classLoader = ExtensionLoader.class.getClassLoader();
// 读取 SPI 资源文件
Enumeration<URL> urls = classLoader != null ? classLoader.getResources(fileName)
: ClassLoader.getSystemResources(fileName);
if (urls != null) {
while (urls.hasMoreElements()) {
URL url = urls.nextElement();
// 构造 classes 缓存, classes 的 K-V 结构为 标识-类对象
loadResources(classes, url);
}
}
}
}private void loadResources(final Map<String, Class<?>> classes, final URL url) throws IOException {
try (InputStream inputStream = url.openStream()) {
Properties properties = new Properties();
properties.load(inputStream);
// 解析资源文件为 KV 结构
properties.forEach((k, v) -> {
String name = (String) k;
String classPath = (String) v;
if (StringUtils.isNotBlank(name) && StringUtils.isNotBlank(classPath)) {
try {
// 加载路径, 传入 classes 缓存、标识、类路径
loadClass(classes, name, classPath);
} catch (ClassNotFoundException e) {
throw new IllegalStateException("load extension resources error", e);
}
}
});
}
}private void loadClass(final Map<String, Class<?>> classes,
final String name, final String classPath) throws ClassNotFoundException {
// 将资源文件中的类路径反射成类对象
Class<?> subClass = Class.forName(classPath);
// 拿到实现类的 Join 注解
Join annotation = subClass.getAnnotation(Join.class);
Class<?> oldClass = classes.get(name);
if (oldClass == null) {
// 放入入参 classes 缓存中, K-V 形式为 标识-类对象
classes.put(name, subClass);
}
}