
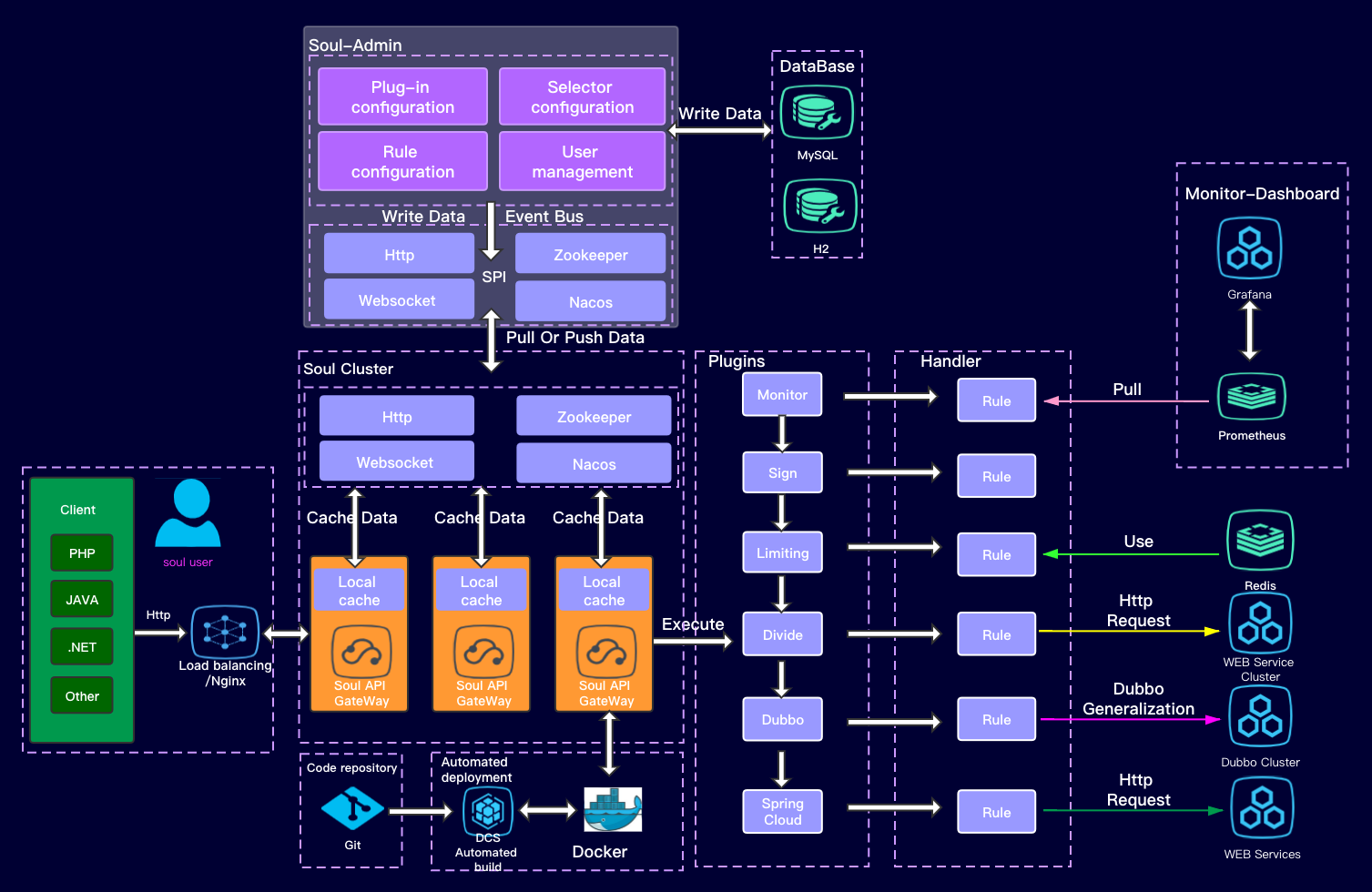
Soul Gateway Learning SPI
Use of SPI in SOUL
When analyzing the load balancing strategy of the divide plug-in, I saw a line of code:
DivideUpstream divideUpstream = LoadBalanceUtils.selector(upstreamList, ruleHandle.getLoadBalance(), ip);At that time, it was easy to skip its implementation, and its function was easy to analyze, calling a method that looked like a tool class, passing in a cluster of multiple nodes, and returning a node. This is a load balancer..
But there are a lot of details, the most important of which is the use of the SPI to select specific implementation classes. Take a look at the code for this method:
public class LoadBalanceUtils {
public static DivideUpstream selector(final List<DivideUpstream> upstreamList, final String algorithm, final String ip) {
// 调用自定义的 SPI 得到一个子类
LoadBalance loadBalance = ExtensionLoader.getExtensionLoader(LoadBalance.class).getJoin(algorithm);
return loadBalance.select(upstreamList, ip);
}
}The latter is to call the select() specific subclass method, according to the different implementation of the subclass, will eventually show a variety of forms. The current subclass implementations are:
- HashLoadBalance
- RandomLoadBalance
- RoundRobinLoadBalance
The key is ExtensionLoader.getExtensionLoader(LoadBalance.class).getJoin(algorithm); this line of work.
Before we look at it, let's take a look at the SPI mechanism provided by Java.
Java SPI
There is such a definition <<高可用可伸缩微服务架构>> 第 3 章 Apache Dubbo 框架的原理与实现 in.
The full name of SPI is Service Provider Interface, which is a built-in service provider discovery function of JDK and a dynamic replacement discovery mechanism. For example, to dynamically add an implementation to an interface at runtime, you only need to add an implementation.
There is also a very vivid brain map in the book, which shows the use of SPI:
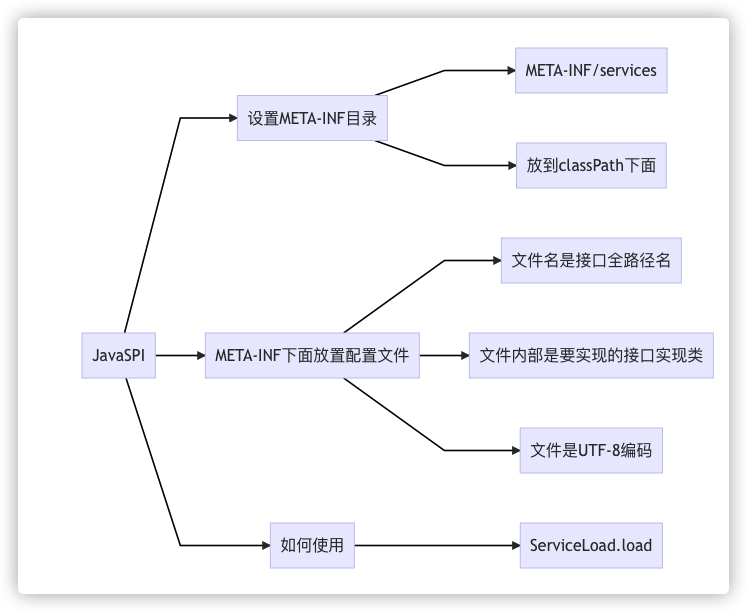
That is to say, in the implementation of our code, there is no need to write a Factory, use MAP to wrap some subclasses, and the final return type is the parent interface. You only need to define the resource file and specify the parent interface and its subclasses in the file, and then you can get all the defined subclass objects by setting them:
ServiceLoader<Interface> loaders = ServiceLoader.load(Interface.class)
for(Interface interface : loaders){
System.out.println(interface.toString());
}Compared with the ordinary factory pattern, this method is definitely more in line with the principle of opening and closing, adding a new subclass without modifying the factory method, but editing the resource file.
Start with a Demo
According to the specification of SPI, I built a demo to see the specific implementation effect.
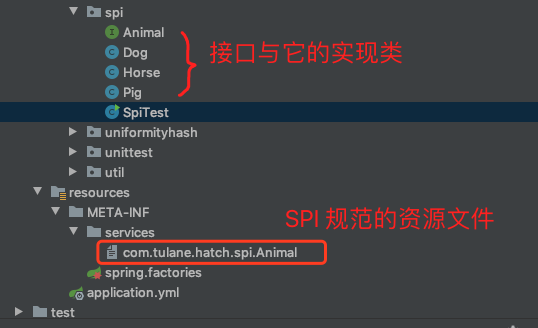
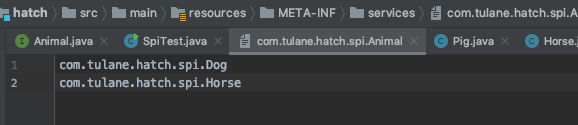
A run() method is defined in Animal, and a subclass implements it.
public interface Animal {
void run();
}
public class Dog implements Animal {
@Override
public void run() {
System.out.println("狗在跑");
}
}
public class Horse implements Animal {
@Override
public void run() {
System.out.println("马在跑");
}
}Use the loading class of SPI to get the execution result of the subclass:
private static void test() {
final ServiceLoader<Animal> load = ServiceLoader.load(Animal.class);
for (Animal animal : load) {
System.out.println(animal);
animal.run();
}
}
After the call, we get the implementation classes previously written in the resource file and successfully invoke their respective run() methods.
At this point, I have a question **, does each call ServiceLoader.load(Animal.class) return the same object? ** If it is, I guess it is loaded into the cache at startup, if not, it may be using reflection at the bottom, and each call has a certain consumption. Let's look at the following experiment:
public static void main(String[] args) {
for (int i = 0; i < 2; i++) {
test();
System.out.println("----------");
}
}
private static void test() {
final ServiceLoader<Animal> load = ServiceLoader.load(Animal.class);
for (Animal animal : load) {
System.out.println(animal);
animal.run();
}
}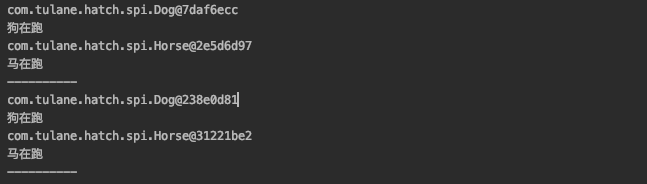
The objects in the two calls are different, which makes me worry about its performance, so let's analyze its code first and see how to implement it.
Implementation of SPI
To find java.util,ServiceLoaders this class, the most striking thing is the directory where we placed the resource files according to the specifications before.
public final class ServiceLoader<S> implements Iterable<S> {
private static final String PREFIX = "META-INF/services/";
}When the debug PREFIX attribute is called, it is found that ServiceLoader.load the lazy loading method is actually used, and the actual return class is not found when it is called, but when it is traversed.
Its lazy loading is implemented in the following code:
public final class ServiceLoader<S> implements Iterable<S> {
public static <S> ServiceLoader<S> load(Class<S> service) {
// 获取当前的类加载器 (我们自己的通常是弟中弟 AppClassLoader )
ClassLoader cl = Thread.currentThread().getContextClassLoader();
return ServiceLoader.load(service, cl);
}
public static <S> ServiceLoader<S> load(Class<S> service, ClassLoader loader) {
// 调用构造器初始化对象 (说明每次调用都使用新的 ServiceLoader 对象)
return new ServiceLoader<>(service, loader);
}
private ServiceLoader(Class<S> svc, ClassLoader cl) {
service = Objects.requireNonNull(svc, "Service interface cannot be null");
loader = (cl == null) ? ClassLoader.getSystemClassLoader() : cl;
acc = (System.getSecurityManager() != null) ? AccessController.getContext() : null;
// 上面都是将信息放入对象实例属性中, 这行才是关键调用
reload();
}
public void reload() {
providers.clear();
// 创建懒加载迭代器, 传入关键的接口 Class 以及加载器
lookupIterator = new LazyIterator(service, loader);
}
}After the call ServiceLoader.load, the key thing is not done, just pass the interface class and loader to LazyIterator, the implementation class of the iterator.
Seeing this, we can guess that when the object returned by the real iteration call is called, the iterator must be required to complete the search and initialization of the implementation class, while the parameter passing is Class information and loader, and the initialization of the implementation class will obviously be reflection.
Take a look at how LazyIterator is implemented, starting with where it will be called hasNext() in the first place:
private class LazyIterator implements Iterator<S> {
public boolean hasNext() {
if (acc == null) {
return hasNextService();
} else {
// ...
}
}
private boolean hasNextService() {
if (nextName != null) {
return true;
}
if (configs == null) {
try {
String fullName = PREFIX + service.getName();
if (loader == null)
configs = ClassLoader.getSystemResources(fullName);
else
// 加载资源文件
configs = loader.getResources(fullName);
} catch (IOException x) {
fail(service, "Error locating configuration files", x);
}
}
while ((pending == null) || !pending.hasNext()) {
if (!configs.hasMoreElements()) {
return false;
}
// 解析出资源文件中写入的实现类类名
pending = parse(service, configs.nextElement());
}
// 获取一个类名
nextName = pending.next();
return true;
}
}
hasNext() The call can get the name of the class in our resource, write it to the instance property nextName, and return it true so that the iterator can make next() the call.
public S next() {
if (acc == null) {
return nextService();
} else {
// ...
}
}
private S nextService() {
if (!hasNextService()) throw new NoSuchElementException();
String cn = nextName;
nextName = null;
Class<?> c = null;
try {
// 反射得到 Class 对象
c = Class.forName(cn, false, loader);
} catch (ClassNotFoundException x) {
fail(service, "Provider " + cn + " not found");
}
if (!service.isAssignableFrom(c)) {
fail(service, "Provider " + cn + " not a subtype");
}
try {
// 初始化对象, 并判断是否与接口符合
S p = service.cast(c.newInstance());
// 将初始化的对象放入hash缓存 (关键步骤)
providers.put(cn, p);
return p;
} catch (Throwable x) {
fail(service, "Provider " + cn + " could not be instantiated", x);
}
throw new Error(); // This cannot happen
}Here we understand that after initialization, the object will be put into the cache, and the key is the interface class. There will be no reflection consumption in the second call.
So why do we produce different object instances in the way we test before? The reason is that each call ServiceLoader.load() produces a new ServiceLoader object. We will improve the test method:
public static void main(String[] args) {
// 复用 ServiceLoaders
final ServiceLoader<Animal> load = ServiceLoader.load(Animal.class);
for (int i = 0; i < 2; i++) {
test(load);
System.out.println("----------");
}
}
private static void test(ServiceLoader<Animal> load) {
for (Animal animal : load) {
System.out.println(animal);
animal.run();
}
}
Java SPI Thinking
There are a lot of details that we haven't described in the Java SPI, but that's the main process. Our two previous questions about how to implement and performance can also be answered:
- How to implement: Read the resource file through the IO stream, load the corresponding path by reflection and generate a Class object, and put it into the cache after initialization
- Performance: The first iteration call will have a reflection call, but when used multiple times, as long as the same ServiceLoader object is used, multiple reflections can be avoided, because the objects in the cache will be reused directly.
At this point, I have a very confused place, before I thought it was very similar to the factory method, but it has an advantage over it, because after adding a subclass, you only need to change the resource file without changing the factory class.
But when I tried to use Java SPI to implement it, I found that it could not achieve this effect. An important reason is ** The individual implementation classes in the resource file are not differentiated ** that I could not filter out the implementation class that I needed to cache in ServiceLoaders.
So where is its usage scenario?
JDBC SPI Usage
According to the information, the most critical pluggable driver design in JDBC is implemented by SPI.
Mysql driver package SPI
In each database connection package, the implementation of JDBC mode needs to implement its Driver interface. The practical one is the SPI mode. Let's take a look.
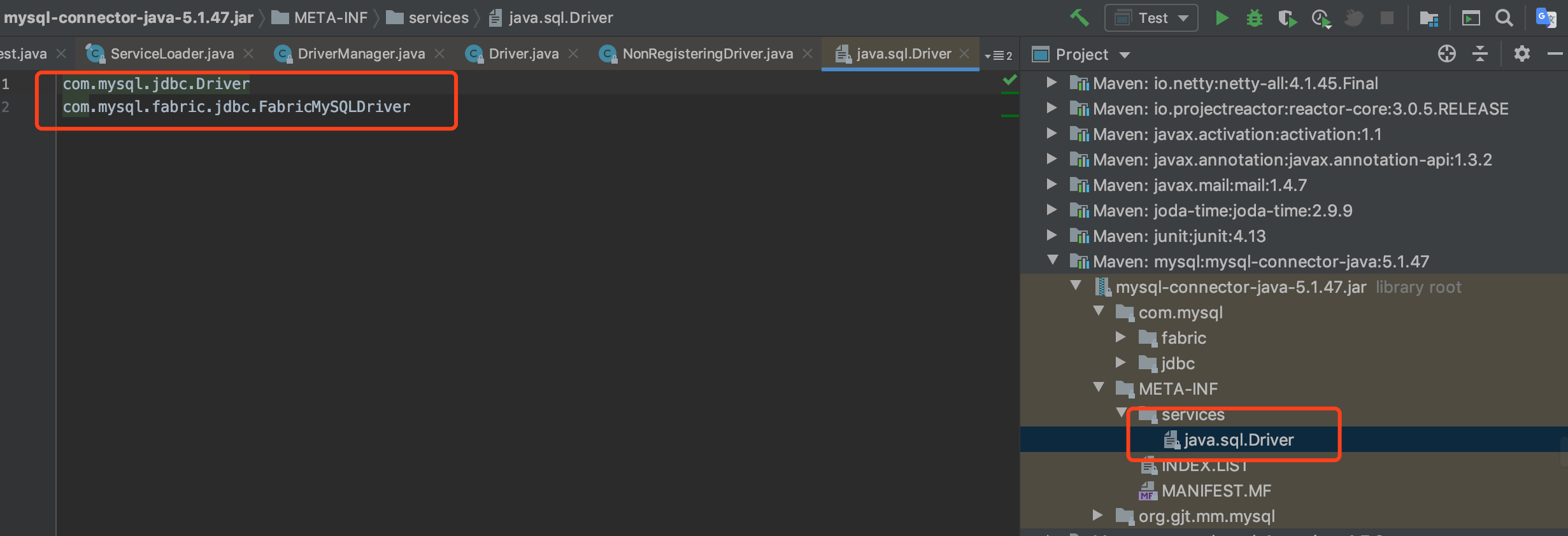
So how do the JDBC-related classes in the JDK implement this? The key class is DriverManager
public class DriverManager {
static {
loadInitialDrivers();
}
private static void loadInitialDrivers() {
// ...
AccessController.doPrivileged(new PrivilegedAction<Void>() {
public Void run() {
// 这里就是 SPI 的实现, 迭代时实际会 Class.forName() 初始化实现类
ServiceLoader<Driver> loadedDrivers = ServiceLoader.load(Driver.class);
Iterator<Driver> driversIterator = loadedDrivers.iterator();
try{
while(driversIterator.hasNext()) {
driversIterator.next();
}
} catch(Throwable t) {
// Do nothing
}
return null;
}
});
// ...
}
}If the static method of DriverManager is called in the code, the above code will be triggered, and what does the initialization of the ** Its function is to initialize all the Driver implementation classes in the SPI resource file. ** implementation class do? Keep looking com.mysql.jdbc.Driver
public class Driver extends NonRegisteringDriver implements java.sql.Driver {
static {
try {
// 调用 DriverManager 的注册方法, 将此 Driver 实现类注册到 JDBC 的 Driver 管理器中
java.sql.DriverManager.registerDriver(new Driver());
} catch (SQLException E) {
throw new RuntimeException("Can't register driver!");
}
}
}The registration method of DriverManager is very simple, that is, the input parameters are put into static variables as a global cache.
public class DriverManager {
// 缓存 Driver 实现类
private final static CopyOnWriteArrayList<DriverInfo> registeredDrivers = new CopyOnWriteArrayList<>();
public static synchronized void registerDriver(java.sql.Driver driver) throws SQLException {
registerDriver(driver, null);
}
public static synchronized void registerDriver(java.sql.Driver driver, DriverAction da) throws SQLException {
if(driver != null) {
// 注册到变量中
registeredDrivers.addIfAbsent(new DriverInfo(driver, da));
} else {
throw new NullPointerException();
}
}
}Filter Driver: Contract is greater than configuration
In normal use, we will get the connection directly DriverManager.getConnection(url, user, passwd), but there is a question here. We have registered multiple drivers in DriverManager. Why can we determine a unique Driver here?
To find the getConnection() DriverManager first:
public static Connection getConnection(String url, String user, String password) throws SQLException {
// ...
return (getConnection(url, info, Reflection.getCallerClass()));
}
private static Connection getConnection(
String url, java.util.Properties info, Class<?> caller) throws SQLException {
// ...
for(DriverInfo aDriver : registeredDrivers) {
// isDriverAllowed() 仅是通过 Class.forName() 初始化, 没有甄别作用
if(isDriverAllowed(aDriver.driver, callerCL)) {
try {
// 最关键的点在这行, 筛选工作其实在实现类自身的 connect() 方法中, 会根据传入的 url 筛选
Connection con = aDriver.driver.connect(url, info);
if (con != null) {
return (con);
}
} catch (SQLException ex) {
}
} else {
}
}
// ...
}See how filtering is implemented in the all-important Mysql Driver (which inherits from NonRegisteringDriver)
public class NonRegisteringDriver implements java.sql.Driver {
private static final String URL_PREFIX = "jdbc:mysql://";
private static final String REPLICATION_URL_PREFIX = "jdbc:mysql:replication://";
private static final String MXJ_URL_PREFIX = "jdbc:mysql:mxj://";
public static final String LOADBALANCE_URL_PREFIX = "jdbc:mysql:loadbalance://";
public java.sql.Connection connect(String url, Properties info) throws SQLException {
// ...
// parseURL() 会匹配 url 是否符合其所在 Driver 的连接方式
// 这里就是采用"约定大于配置"的思想, 通过匹配路径头做筛选
if ((props = parseURL(url, info)) == null) {
return null;
}
// ...
}
public Properties parseURL(String url, Properties defaults) throws java.sql.SQLException {
// ...
// 如果 url 不匹配此 Driver 的路径则返回null, 最外层会继续尝试下个 Driver
if (!StringUtils.startsWithIgnoreCase(url, URL_PREFIX) && !StringUtils.startsWithIgnoreCase(url, MXJ_URL_PREFIX)
&& !StringUtils.startsWithIgnoreCase(url, LOADBALANCE_URL_PREFIX) && !StringUtils.startsWithIgnoreCase(url, REPLICATION_URL_PREFIX)) {
return null;
}
// ...
}
}Summary MySQL & JDBC
See here, I think you already understand the implementation of SPI in MySQL & JDBC. Summarize a few points.
- The DriverManager in JDBC loads the SPI resource file and
java.sql.Driverinitializes all the implementation classes. - In fact, when the class is initialized, it will create its own object and inject it into DriverManager for unified management.
- The DriverManager filters the managed Drivers by the Driver implementation class itself, which is only responsible for traversing and taking out the available Drivers
- The Driver implementation class determines whether it should return itself by passing in the database URL header. If not, return
null.. JDBC's DriverManager receives thenullcall that will continue with the next Driver implementation class. - The MySql driver actual selection scheme is path header matching, which is one of
JDBC Demo
After writing these analyses, let's look at how to implement a simple demo.
Let's share the way I wrote it before.
static {
try {
// 反射, 该类加载时会在静态块中, 向 DriverManager 注册 Driver
Class.forName("com.mysql.jdbc.Driver");
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
try (
final Connection conn = DriverManager.getConnection(url, user, passwd);
final Statement stmt = conn.createStatement();
final ResultSet rs = stmt.executeQuery("select count(1) from test")
) {
while (rs.next()) {
int count = rs.getInt("count(1)");
System.out.println(count);
}
} catch (Exception e) {
e.printStackTrace();
}
}Although this can be used, don't you think there is extra code? Look at my new way of writing.
public static void main(String[] args) throws ClassNotFoundException {
try (
final Connection conn = DriverManager.getConnection(url, user, passwd);
final Statement stmt = conn.createStatement();
final ResultSet rs = stmt.executeQuery("select count(1) from test")
) {
while (rs.next()) {
int count = rs.getInt("count(1)");
System.out.println(count);
}
} catch (Exception e) {
e.printStackTrace();
}
}Only these simple codes are needed. DriverManager.getConnection() When called, the DriverManager will automatically load the implementation class in the SPI, and we do not need to Class.forName() manually call java.mysql.Driver the initialization.
** See here I think you still understand the most important role of SPI. There is no need to explicitly write out the implementation class corresponding to the interface **
So we also have a problem in "Java SPI Thinking" that has been solved. ** How do you distinguish the implementation classes to be used in the SPI? Let the implementation class decide for itself, and the outer call simply iterates over all. **
SOUL SPI implementation
We have a thorough understanding of the use of SPI in Java, while the SPI in Soul is designed by ourselves, using the design idea of SPI in Dubbo. You can see the associated annotation on the org.dromara.soul.spi.SPI annotation class.
/**
* SPI Extend the processing.
* All spi system reference the apache implementation of
* https://github.com/apache/dubbo/blob/master/dubbo-common/src/main/java/org/apache/dubbo/common/extension.
*/Java SPI bug
When analyzing the use of Java SPI in the last two modules, some shortcomings were found:
- If the ServiceLoader is used improperly ** Does not properly utilize its caching mechanism **, it will cause the class object to be reflected and the instance object to be initialized every time the concrete implementation class is obtained. Not to mention that the performance is over, the object obtained every time is different, which may cause program problems.
- That is to say, every time you look for a specific implementation class, you have to iterate over it. Although the use of fewer subclasses has no effect, this way is still silly. In addition, referring to the implementation of JDBC in MySQL driver, we also need to design a more complex filtering mechanism.
So how does the implementation of Soul SPI solve these two problems? The key lies in the next two sub-modules.
- Optimized Extension Loader
- Enhanced getJoin ()
Optimized Extension Loader
Let's first look at the overall picture of the SPI implementation project, which is soul-spi:
The core class is the Extension Loader, which can be said to be the Soul version of the ServiceLoader. It also defines the path location of the SPI resource file.
public final class ExtensionLoader<T> {
private static final String SOUL_DIRECTORY = "META-INF/soul/";
}By examining the callers of its methods, we find the entry method.
public final class ExtensionLoader<T> {
private static final Map<Class<?>, ExtensionLoader<?>> LOADERS = new ConcurrentHashMap<>();
public static <T> ExtensionLoader<T> getExtensionLoader(final Class<T> clazz) {
// ...
// 根据加载类对象取出缓存中数据, 如果没有则新建 ExtensionLoader 对象并放入缓存
ExtensionLoader<T> extensionLoader = (ExtensionLoader<T>) LOADERS.get(clazz);
if (extensionLoader != null) {
return extensionLoader;
}
LOADERS.putIfAbsent(clazz, new ExtensionLoader<>(clazz));
return (ExtensionLoader<T>) LOADERS.get(clazz);
}
}This method acts like a ServiceLoader load() method and returns a ServiceLoader object.
It's just that the implementation in Soul changes the way it caches the Extension Loader object so that
Enhanced search getJoin ()
Let's look at the getJoin() Extension Loader method, which I understand as ** Better implementation of ServiceLoader Iterator Edition **. It also does two things that the ServiceLoader iteration did:
Initialize the implementation class in the SPI
Cache the implementation class-> as a Map collection of the form Key-Value
Based on the K-V cache mode, it also made a transformation that I was most looking forward to:
- The direct matching of time complexity
O(1)to realize class mode
Multi-tier cache
The reason ExtensionLoader can do this enhanced search without iterating over everything each time is that it relies on three different types of caching.
These three caches are divided into two layers, each of which has different purposes. The overview is as follows:
// 一层缓存
private final Map<String, Holder<Object>> cachedInstances = new ConcurrentHashMap<>();
// 二层缓存之一
private final Holder<Map<String, Class<?>>> cachedClasses = new Holder<>();
// 二层缓存之一
private final Map<Class<?>, Object> joinInstances = new ConcurrentHashMap<>();Tier 1 cache: cachedInstances
The first is the first-tier cache, which is the first thing we come into contact with when searching for the specific implementation class of the interface. If we hit it, we can directly get the object of the implementation class.
private final Map<String, Holder<Object>> cachedInstances = new ConcurrentHashMap<>();It key is actually the information we configured in the Soul SPI resource file, such as the resource file of the load balancing implementation class of the Divide plug-in.
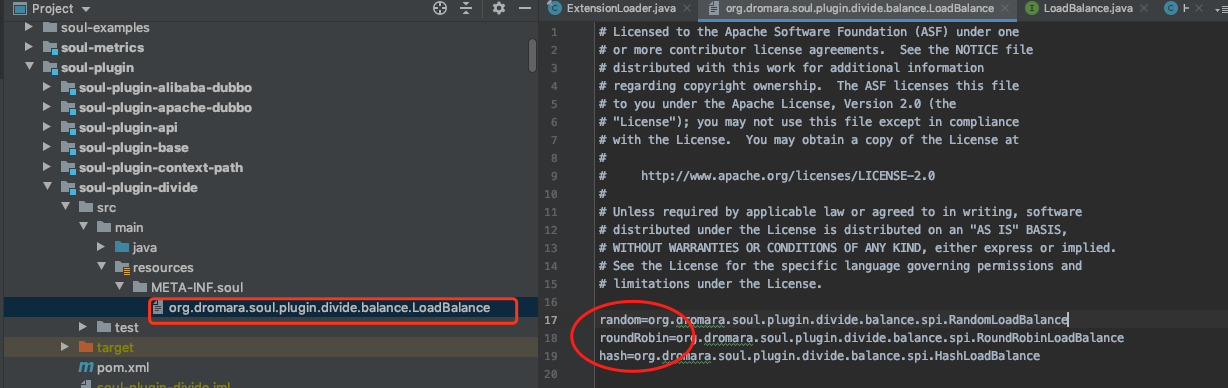
And it value 's the Holder object, which holds the object of the implementation class. When called getJoin(), pass in an identity (such as random) to get the implementation class object.
public T getJoin(final String name) {
// ...
Holder<Object> objectHolder = cachedInstances.get(name);
Object value = objectHolder.getValue();
// ...
return (T) value;
}Layer 2 Cache: cachedClasses
It cachedClasses stores the mapping between the identity (random) and the class object
private final Holder<Map<String, Class<?>>> cachedClasses = new Holder<>();How is the cachedClasses cached information populated? Is directly triggered to retrieve the SPI resource file and then parse it into a cachedClasses cache. The specific method is in loadResources()
private void loadResources(final Map<String, Class<?>> classes, final URL url) throws IOException {
Properties properties = new Properties();
// 解析资源文件
properties.load(inputStream);
properties.forEach((name, classPath) -> {
// 读出 K-V 结构并组装成 classes, 外层调用会包装到 cachedClasses
loadClass(classes, name, classPath);
});
}Second-tier cache: joinInstances
The joinInstances cache holds the mapping of class objects to object instances.
private final Map<Class<?>, Object> joinInstances = new ConcurrentHashMap<>();This layer of cache will get the class object of the corresponding identifier (random) with the help of the second layer of cache, and cache it into itself through the initialization instance of the class object. The corresponding implementation method is as follow
private T createExtension(final String name) {
Class<?> aClass = getExtensionClasses().get(name);
Object o = joinInstances.get(aClass);
if (o == null) {
joinInstances.putIfAbsent(aClass, aClass.newInstance());
}
return (T) o;
}Cache summary
When the implementation class of an interface is loaded through the Extension Loader, the flow chart of the cache call is as follows:
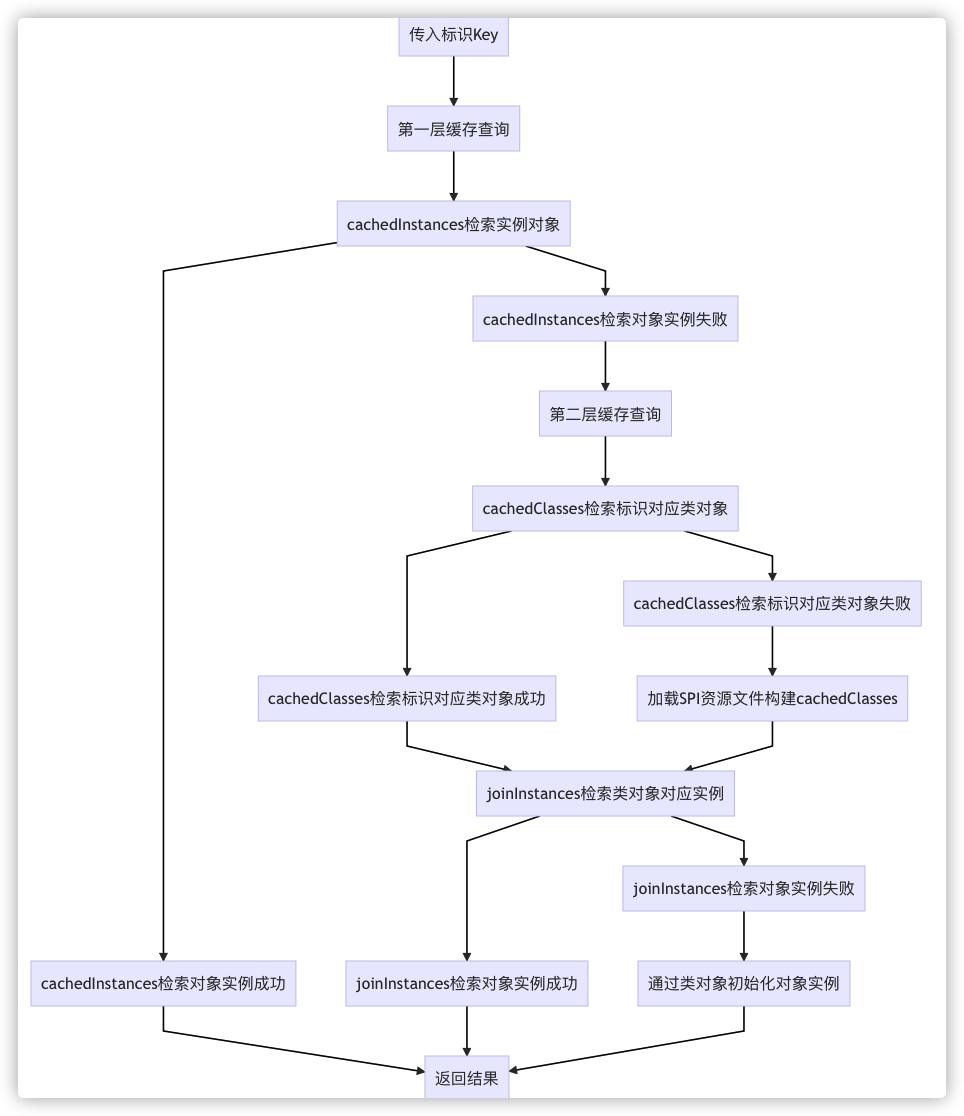
Detailed source code analysis (can be skipped)
// name can be understood as an identifier used to distinguish a specific implementation class in the SPI file.
public T getJoin(final String name) {
// ...
// cachedInstances caches all Holder objects. The value property of the Holder object holds the concrete implementation class.
// I understand cachedInstances as the first-level cache. If it hits, it directly returns the desired class.
Holder<Object> objectHolder = cachedInstances.get(name);
if (objectHolder == null) {
cachedInstances.putIfAbsent(name, new Holder<>());
objectHolder = cachedInstances.get(name);
}
Object value = objectHolder.getValue();
// Double-checked locking: if not hit, call createExtension()
if (value == null) {
synchronized (cachedInstances) {
value = objectHolder.getValue();
if (value == null) {
value = createExtension(name);
objectHolder.setValue(value);
}
}
}
return (T) value;
}private T createExtension(final String name) {
// Critical code, searching for the class object corresponding to the identifier.
Class<?> aClass = getExtensionClasses().get(name);
if (aClass == null) {
throw new IllegalArgumentException("name is error");
}
// joinInstances can be understood as the second-level cache, where K-V maps class objects to their initialized instances.
Object o = joinInstances.get(aClass);
if (o == null) {
try {
joinInstances.putIfAbsent(aClass, aClass.newInstance());
o = joinInstances.get(aClass);
} catch (InstantiationException | IllegalAccessException e) {
// ...
}
}
return (T) o;
}public Map<String, Class<?>> getExtensionClasses() {
// cachedClasses is the third-level cache, storing the mapping of identifiers to class objects.
Map<String, Class<?>> classes = cachedClasses.getValue();
if (classes == null) {
synchronized (cachedClasses) {
classes = cachedClasses.getValue();
if (classes == null) {
// Construct the classes cache, with K-V structure as identifier-class object.
classes = loadExtensionClass();
cachedClasses.setValue(classes);
}
}
}
return classes;
}private Map<String, Class<?>> loadExtensionClass() {
// Get the SPI annotation of the interface.
SPI annotation = clazz.getAnnotation(SPI.class);
if (annotation != null) {
String value = annotation.value();
if (StringUtils.isNotBlank(value)) {
cachedDefaultName = value;
}
}
// Construct the classes cache, with K-V structure as identifier-class object.
Map<String, Class<?>> classes = new HashMap<>(16);
loadDirectory(classes);
return classes;
}private void loadDirectory(final Map<String, Class<?>> classes) {
String fileName = SOUL_DIRECTORY + clazz.getName();
try {
ClassLoader classLoader = ExtensionLoader.class.getClassLoader();
// Read the SPI resource file.
Enumeration<URL> urls = classLoader != null ? classLoader.getResources(fileName)
: ClassLoader.getSystemResources(fileName);
if (urls != null) {
while (urls.hasMoreElements()) {
URL url = urls.nextElement();
// Construct the classes cache, with K-V structure as identifier-class object.
loadResources(classes, url);
}
}
}
}private void loadResources(final Map<String, Class<?>> classes, final URL url) throws IOException {
try (InputStream inputStream = url.openStream()) {
Properties properties = new Properties();
properties.load(inputStream);
// Parse the resource file into K-V structure.
properties.forEach((k, v) -> {
String name = (String) k;
String classPath = (String) v;
if (StringUtils.isNotBlank(name) && StringUtils.isNotBlank(classPath)) {
try {
// Load the class path into classes cache, along with identifier and class path.
loadClass(classes, name, classPath);
} catch (ClassNotFoundException e) {
throw new IllegalStateException("load extension resources error", e);
}
}
});
}
}private void loadClass(final Map<String, Class<?>> classes,
final String name, final String classPath) throws ClassNotFoundException {
// Reflect the class path from the resource file into a class object.
Class<?> subClass = Class.forName(classPath);
// Get the Join annotation of the implementation class.
Join annotation = subClass.getAnnotation(Join.class);
Class<?> oldClass = classes.get(name);
if (oldClass == null) {
// Put it into the classes cache as K-V, with identifier as the key and class object as the value.
classes.put(name, subClass);
}
}