

原生Java人工智能算法框架 easyAI v1.2.6版本更新
前言
EasyAi的出现对于Java的意义,等同于在JavaWeb领域spring出现的意义一样——做一个开箱即用,让每一个开发者都可以使用EasyAi,来开发符合自己人工智能业务需求的小微模型,这就是它的使命!
EasyAi介绍
EasyAi无任何依赖,它是一个原生Java人工智能算法框架。首先,**它可以Maven一键丝滑引入我们的Java项目,无需任何额外的环境配置与依赖,做到开箱即用。**再者,它既有一些我们已经封装好的图像目标检测及人工智能客服的模块,也提供各种深度学习,机器学习,强化学习,启发式学习,矩阵运算,等底层算法工具。开发者可以通过简单的学习,就能完成根据自身业务,深度开发符合自己业务的小微模型
EasyAI码云下载链接:https://gitee.com/dromara/easyAi
EasyAI技术文档地址:https://www.myeasyai.cn/
EasyAI详细视频教程:https://www.bilibili.com/video/av89134035
EasyAI框架0基础深度开发及人工智能完整体系教程:https://www.bilibili.com/cheese/play/ss17600
v1.2.6 更新内容
词向量嵌入器与TransFormer已经能支持自定义词粒度训练
**小技巧:**开发者在进行词向量训练样本时,需要考虑“词粒度”,如果训练样本相对较少,则设置更粗的词粒度,会产生更好的效果。例如训练:
select * from student这么一句sql语句,如果不考虑词粒度完全用默认最低词粒度,即单个字符作为词粒度,那么我们生成的时候,是以s,e,l,e,c,t...... 这种基本单位形式进行训练与生成的。但如果我们考虑词粒度,可以以
select,*,from,student更粗的粒度作为训练的基本单位,如果若干固定字符总以一个整体进行展示,那么设置合适的词粒度进行训练,我们的效率和稳定性必然要高很多。
语句模板实体类增加新 构造参数和方法来配合自定义词粒度
SentenceModel为词向量嵌入提供的,装载所有语句的模板类
public SentenceModel(String splitWord)可以带间隔符构造参数的构造方法,若开发者要自定义词粒度粗细,使用设置间隔符,使用间隔符间隔语句之间的词,自定义控制词粒度粗细。例如:
select * from student该语句中的词语之间使用隔符"空格",那么可以使用带间隔符的构造方法SentenceModel s = new SentenceModel(" "),这样训练时词向量嵌入器会将select,*,from,student作为一个整体进行训练,间隔符可自定义。如果开发者使用无构造参数的构造方法,则词向量嵌入器会默认将每个单个字符作为一个整体进行训练。注意:小训练样本往往设置更粗的粒度有助于稳定性,目前自定义粒度粗细,只对依赖TransFormer的方法有效参数
String splitWord为自定义词粒度间隔符
public SentenceModel()无参构造,无参构造会默认以最小词粒度,即每个字符作为一个整体进行词向量训练。
public void setSentence(String sentence)向语句模板实体类里面输入一句话(训练样本),该样本语句为无间隔符样本语句。该方法无论是使用无参构造,还是带间隔符参数构造本类都可调用。
public void setSentenceBySplitWord(String sentence)向语句模板实体类里面输入一句话(训练样本),该样本语句为携带间隔符的样本语句。若使用该方法,必须以public SentenceModel(String splitWord)带间隔符参数,来构造本类,才可调用。
TF参数配置类 增加了两个新参数来增强业务稳定性
private String splitWord设置词粒度间隔符,注意:该间隔符的设置必须与语句模板实体类中的构造参数设置的间隔符一致!。若无需间隔符,该值可设置为null,但同时语句模板实体类也必须使用对应的无参构造。
private boolean selfTimeCode是否使用自增时间序列位置编码,若为true则tf位置编码使用按时间序列,均匀自增。若为false则tf位置编码使用对称三角函数位置编码使用对称三角函数位置编码与自增编码在不同的业务环境下,表现不同。通常来说开发生成式语句,使用对称三角函数位置编码效果表现会更好,而做语句语义分类使用自增位置编码效果会更好,但这只是个参考并不绝对,通常建议该参数作为调参的尝试,都试一试,则优取之。
词向量嵌入器配合自定义词粒度更新,获取词向量矩阵的api
public MyWordFeature getEmbedding(String word, long eventId, boolean once)获取一段话(或词)的词向量矩阵实体类。参数
String word要获取词向量的一段话或者词参数
boolean once是否进行一次性获取,若该参数为false则本次调用是对一段话参数String word按每个字符单位获取词向量,根据该段话的字符顺序从0开始向下行排列构成一句话的一个词向量矩阵,每一个字的词向量占据词向量矩阵实体类中的词向量矩阵的一行。若该参数为true,则是对词参数String word看作一个整体,直接获取该词对应的向量,当它为true时,通常是跟有间隔符设置词粒度时,同时相关使用。参数
long eventId为执行的生命周期内,线程安全唯一ID
以下是该方法演示的一个简单的小DEMO(中文自动生成 sql语句),注意这只是演示用法的demo,只有三条样本数据,只能作为演示api用法用途:
public class Test {
public static TfConfig config = new TfConfig();//最外层配置文件
public static WordEmbedding wordEmbedding = new WordEmbedding();//词向量嵌入器
public static int wordVectorDimension = 32;//设置词向量维度
public static TalkToTalk talk;
public static void main(String[] args) throws Exception {
init();//初始化操作
//creat();//生成
study();//训练
}
public static void creat() throws Exception {
wordEmbedding.insertModel(readWordModel(), wordVectorDimension);//将模型文件反序列化为模型实体类,加载词向量模型
talk = new TalkToTalk(wordEmbedding, config);//创建长语句对话类
talk.init();//初始化长语句对话类
talk.insertModel(readTalkModel());//长语句对话类加载tf模型
//注意以上部分为初始化且加载模型部分,在服务启动时执行且只执行一次。不需要每次识别都加载模型!
//TalkToTalk在实际使用中必须单例!实际调用getAnswer进行识别的TalkToTalk不能是new出来的!
//而是直接获取服务启动时,初始化加载好的单例类。如果每次识别都要加载一次模型的话,整个过程会非常耗时!
String a = talk.getAnswer("查询#的学生信息", 1);//输入问题,返回答案
System.out.println(a);//最终输出:select * from student where id = #
}
public static void init() {
wordEmbedding.setConfig(new SentenceConfig());//词向量设置配置类
wordEmbedding.setStudyTimes(100);//词向量训练循环100次
config.setMaxLength(40);//最大长度设置为40
config.setMultiNumber(2);//每层编解码器设置2个多头
config.setFeatureDimension(wordVectorDimension);//设置词向量维度
config.setAllDepth(1);//设置tf编解码器深度
config.setSplitWord(" ");//设置空格为词隔断符
config.setSelfTimeCode(false);//设置为对称三角函数位置编码
config.setTimes(500);//循环训练五百次
config.setStudyPoint(0.01);//设置tf学习率
config.setShowLog(true);//对学习中的数据打印
config.setRegularModel(RZ.NOT_RZ);//无正则模式
config.setRegular(0.0);//无正则系数
}
public static void study() throws Exception {
SentenceModel sentenceModel = new SentenceModel(config.getSplitWord());//设置隔断符训练样本类
List<TalkBody> talkBodies = data();//读取测试数据
for (TalkBody value : talkBodies) {//塞入测试数据
sentenceModel.setSentence(value.getQuestion());//将问题塞入无隔断符样本类
sentenceModel.setSentenceBySplitWord(value.getAnswer());//将回答塞入有隔断符号样本类
}
wordEmbedding.init(sentenceModel, wordVectorDimension);//初始化词向量嵌入
WordTwoVectorModel wordTwoVectorModel = wordEmbedding.start();//词向量训练完毕,并返回词向量模型
talk = new TalkToTalk(wordEmbedding, config);//创建长语句对话类
talk.init();//初始化长语句对话类
TransFormerModel transFormerModel = talk.study(talkBodies);//训练完毕并返回tf模型。
Tools.writeModel(JSONObject.toJSONString(wordTwoVectorModel), "/Users/lidapeng/job/testDocument/model/testWord.json");//写出模型
Tools.writeModel(JSONObject.toJSONString(transFormerModel), "/Users/lidapeng/job/testDocument/model/testTalk.json");//写出模型
}
private static WordTwoVectorModel readWordModel() {//读模型
File file = new File("/Users/lidapeng/job/testDocument/model/testWord.json");
String a = Tools.readPaper(file);
return JSONObject.parseObject(a, WordTwoVectorModel.class);
}
private static TransFormerModel readTalkModel() {//读模型
File file = new File("/Users/lidapeng/job/testDocument/model/testTalk.json");
String a = Tools.readPaper(file);
return JSONObject.parseObject(a, TransFormerModel.class);
}
public static List<TalkBody> data() {//配置测试用三条训练数据
List<TalkBody> talkBodies = new ArrayList<>();
TalkBody talkBody1 = new TalkBody();
TalkBody talkBody2 = new TalkBody();
TalkBody talkBody3 = new TalkBody();
talkBody1.setQuestion("查询#的学生信息");//查询名字叫做#的学生信息
talkBody1.setAnswer("select * from student where id = #");
talkBody2.setQuestion("添加id为#,年龄17的学生信息");
talkBody2.setAnswer("insert into student ( id , age ) values ( # , 17 )");
talkBody3.setQuestion("将#的年龄改为18");
talkBody3.setAnswer("update student set age = 18 where id = #");
talkBodies.add(talkBody1);
talkBodies.add(talkBody2);
talkBodies.add(talkBody3);
return talkBodies;
}
}人脸检测效果演示

图像识别FastYolo效果展示
- 使用EasyAi实现图像结算自动贩卖机视觉内核

sayOrder人工智能客服
sayOrder是依赖EasyAi进行封装的人工智能客服系统。
它可以分析用户输入的语义,来识别用户的行为,并通过typeID来区分用户意图ID。并通过捕捉其后台设置的关键词类别,来抓出系统关心的用户在语句中包含的内容,比如语句中的时间,地点等。
它还可以与用户自主进行问答交互,进行自主解答疑问或者进行其余意图的交流等。
项目链接地址: https://gitee.com/dromara/sayOrder
sayOrder交互基本业务流程演示
用户第一次进行输入表达自己的想法
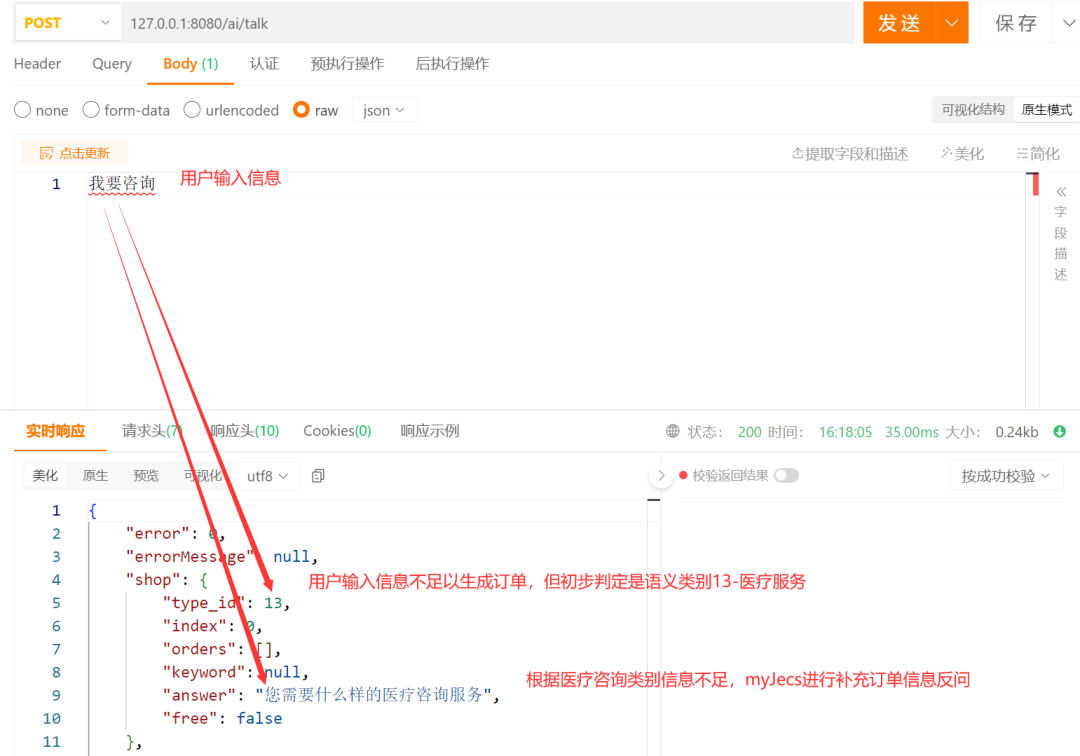
SayOrder发现用户的描述缺少订单必要信息,则进行反问。用户接收到SayOrder的反问,进一步补充的自己的想法
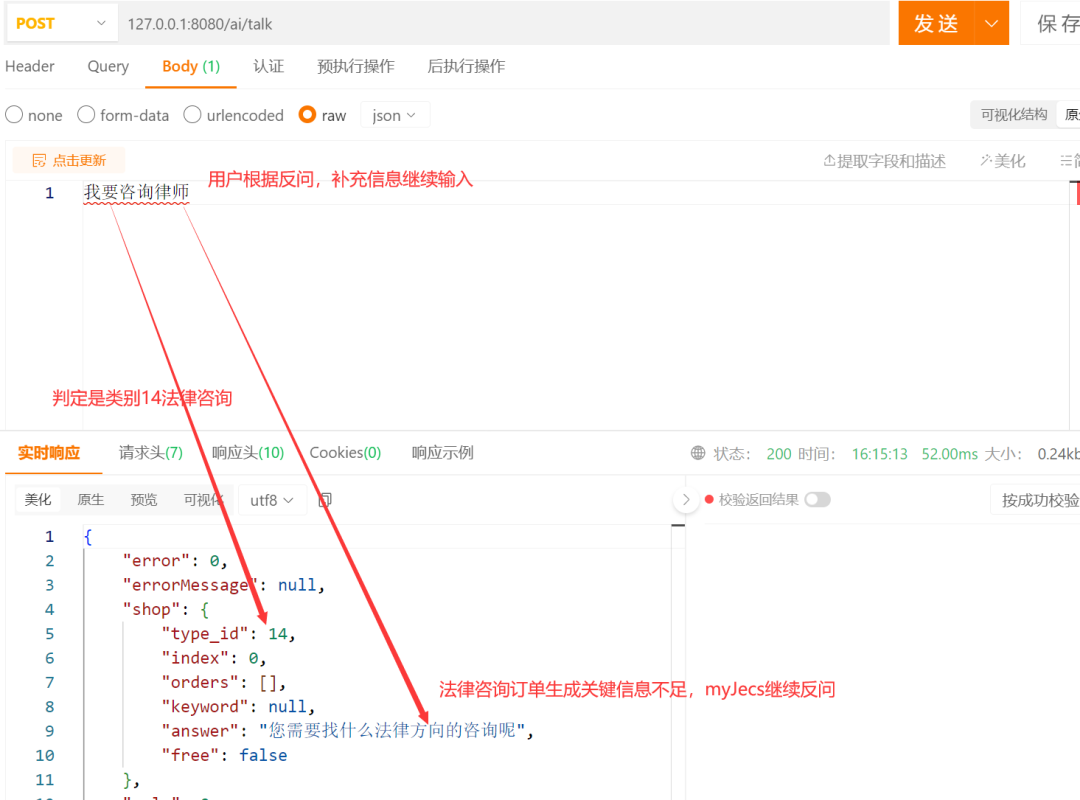
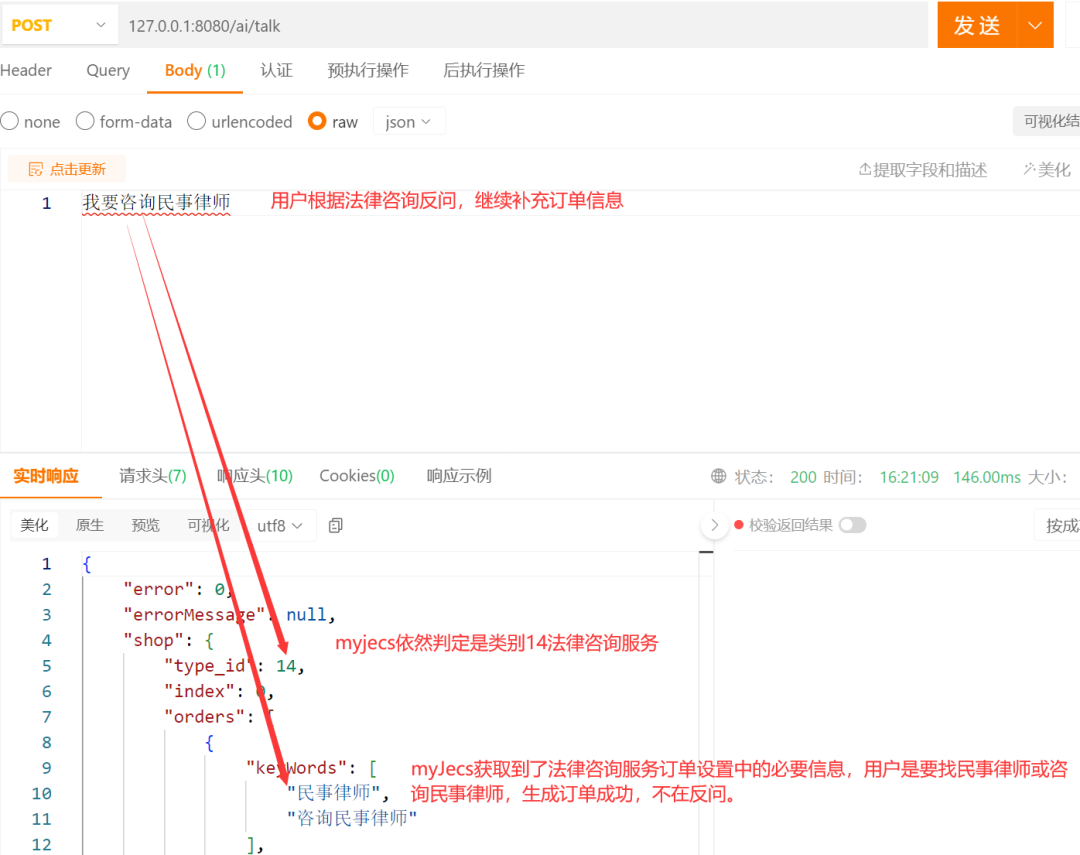
用户第二次输入信息依然不满足后台14分类法律咨询的订单关键信息要求,继续补充信息,最终完成订单信息补充生成订单。
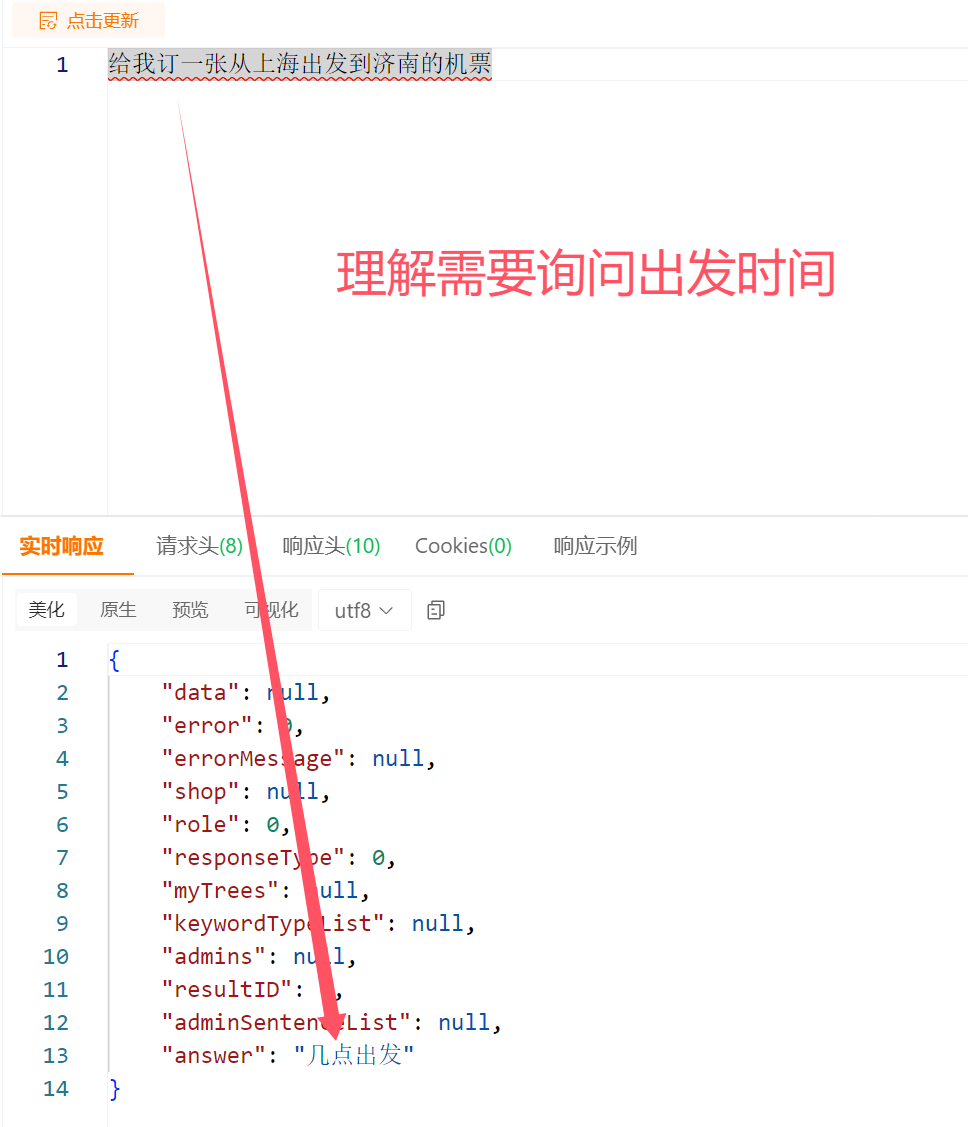
用户输入想要咨询的问题,SayOrder对用户咨询的问题进行自主解答
架构设计
常用底层算法模块
基础矩阵及线代计算模块:
1.内置矩阵类,矩阵计算类,可以完成常用矩阵四则运算,奇偶性,多元线性回归,逻辑斯蒂回归,欧式距离,余弦相似性,im2col,逆im2col,求代数余子式,求逆,求伴随矩阵,内积等,微分等一系列api。
2.RGB三通道矩阵,可进行图像转化,剪切,分块,生成图像矩阵等操作方便后续计算。
机器学习-聚类:
k聚类,混合高斯聚类,密度聚类,学习向量量化聚类等
机器学习-分类及拟合:多层前馈神经网络,多层循环神经网络,残差网络,多层残差循环神经网络,卷积神经网络,决策树,随机森林,k最近邻等
启发式算法:粒子群,蚁群,模拟退火
强化学习 动态规划,蒙特卡洛分析,马尔可夫,时序差分
常用上层算法模块
视觉图像:图像识别,图片摘要,目标检测
自然语言:语义理解,拆词分词,推理敏感及关键词,语句补全,语言交流
游戏机器人:自主策略,自主行动
使用
1.将项目下载后打包进本地maven库
2.将easyAi pom文件引入地址引入项目
关注项目
- 对项目有什么想法或者建议与学习,都可以加我工作微信

关于 Dromara
Dromara 是由国内顶尖的开源项目作者共同组成的开源社区。提供包括分布式事务,流行工具,企业级认证,微服务RPC,运维监控,Agent监控,分布式日志,调度编排等一系列开源产品、解决方案与咨询、技术支持与培训认证服务。技术栈全面开源共建、 保持社区中立,致力于为全球用户提供微服务云原生解决方案。让参与的每一位开源爱好者,体会到开源的快乐。
Dromara开源社区目前拥有10+GVP项目,总star数量超过十万,构建了上万人的开源社区,有成千上万的个人及团队在使用Dromara社区的开源项目。
欢迎大家来到知识星球和我互动
