

Native Java Artificial Intelligence Algorithm Framework easyAI v1.2.6 Version Update
Foreword
The significance of EasyAi for Java is equivalent to the role of Spring in the JavaWeb field—to provide an out-of-the-box solution that enables every developer to use EasyAi to develop small-scale models that meet their artificial intelligence business needs. This is its mission!
Introduction to EasyAi
EasyAi has no dependencies. It is a native Java artificial intelligence algorithm framework. Firstly, it can be seamlessly integrated into our Java projects with Maven in one step, without any additional environment configuration or dependencies, achieving out-of-the-box usability. Secondly, it includes pre-packaged modules for image target detection and AI customer service, as well as underlying algorithm tools for deep learning, machine learning, reinforcement learning, heuristic learning, matrix operations, and more. Developers can, with minimal learning, develop small-scale models that deeply align with their business needs.
- EasyAI Gitee download link: https://gitee.com/dromara/easyAi
- EasyAI technical documentation: https://www.myeasyai.cn/
- EasyAI detailed video tutorials: https://www.bilibili.com/video/av89134035
- EasyAI framework zero-based deep development and complete AI system tutorials: https://www.bilibili.com/cheese/play/ss17600
v1.2.6 Update Content
Word Embedder and TransFormer Now Support Custom Word Granularity Training
Tip: When preparing training samples for word embedding, developers need to consider "word granularity." If the training samples are relatively few, setting a coarser word granularity can yield better results. For example, when training the SQL statement
select * from student, if the default minimal word granularity (i.e., single characters as word granularity) is used without considering word granularity, the training and generation will be based on basic units likes,e,l,e,c,t.......However, if we consider word granularity, we can use coarser units like
select,*,from,studentas the basic units for training. If certain fixed characters always appear as a whole, setting an appropriate word granularity for training will significantly improve efficiency and stability.
Sentence Template Entity Class Adds New Constructor Parameters and Methods to Support Custom Word Granularity
SentenceModelis a template class for word embedding, designed to load all sentences.
public SentenceModel(String splitWord)is a constructor method that accepts a delimiter parameter. If developers want to customize the coarseness of word granularity, they can use this method to set a delimiter to separate words in sentences, thereby controlling the word granularity.For example: In the statement
select * from student, the words are separated by a "space" delimiter. Thus, the constructor method with a delimiter parameter can be used:SentenceModel s = new SentenceModel(" "). This way, during training, the word embedder will treatselect,*,from, andstudentas whole units for training. The delimiter can be customized. If developers use the parameterless constructor, the word embedder will default to treating each single character as a whole unit for training. Note: For small training samples, setting a coarser granularity often helps with stability. Currently, custom granularity only affects methods dependent on TransFormer.Parameter
String splitWordis the custom word granularity delimiter.
public SentenceModel()is a parameterless constructor. Using this constructor will default to the minimal word granularity, where each character is treated as a whole unit for word embedding training.
public void setSentence(String sentence)inputs a sentence (training sample) into the sentence template entity class. The sample sentence is a sentence without delimiters. This method can be called whether using the parameterless constructor or the constructor with a delimiter parameter.
public void setSentenceBySplitWord(String sentence)inputs a sentence (training sample) into the sentence template entity class. The sample sentence is a sentence with delimiters. If this method is used, the class must be constructed usingpublic SentenceModel(String splitWord)with a delimiter parameter.
TF Configuration Class Adds Two New Parameters to Enhance Business Stability
private String splitWordsets the word granularity delimiter. Note: This delimiter must match the delimiter set in the constructor parameter of the sentence template entity class! If no delimiter is needed, this value can be set tonull, but the sentence template entity class must also use the corresponding parameterless constructor.
private boolean selfTimeCodedetermines whether to use an auto-incrementing time series positional encoding. Iftrue, the TF positional encoding uses a uniformly auto-incrementing time series. Iffalse, the TF positional encoding uses symmetric trigonometric positional encoding.The performance of symmetric trigonometric positional encoding and auto-incrementing encoding varies under different business environments. Generally, for generative sentences, symmetric trigonometric positional encoding performs better, while for sentence semantic classification, auto-incrementing positional encoding performs better. However, this is only a reference and not absolute. It is recommended to treat this parameter as a tuning attempt and choose the best-performing option.
Word Embedder Updated to Support Custom Word Granularity, with API for Retrieving Word Vector Matrix
public MyWordFeature getEmbedding(String word, long eventId, boolean once)retrieves the word vector matrix entity class for a phrase (or word).Parameter
String wordis the phrase or word for which the word vector is to be retrieved.Parameter
boolean oncedetermines whether to retrieve it as a one-time operation. Iffalse, this method call retrieves the word vector for each character unit in the phraseString word, arranging them in order from top to bottom to form a word vector matrix for the sentence. Each character's word vector occupies a row in the word vector matrix entity class. Iftrue, the word parameterString wordis treated as a whole, directly retrieving the vector corresponding to the word. This is typically used in conjunction with delimiter-based word granularity settings.Parameter
long eventIdis the thread-safe unique ID for the execution lifecycle.
Below is a simple demo (Chinese automatic SQL statement generation) demonstrating the usage of this method. Note that this is only a demo with three sample data points and is intended solely for demonstrating API usage:
public class Test {
public static TfConfig config = new TfConfig(); // Outer configuration file
public static WordEmbedding wordEmbedding = new WordEmbedding(); // Word embedder
public static int wordVectorDimension = 32; // Set word vector dimension
public static TalkToTalk talk;
public static void main(String[] args) throws Exception {
init(); // Initialization
// creat(); // Generate
study(); // Train
}
public static void creat() throws Exception {
wordEmbedding.insertModel(readWordModel(), wordVectorDimension); // Deserialize model file into model entity class, load word vector model
talk = new TalkToTalk(wordEmbedding, config); // Create long-sentence dialogue class
talk.init(); // Initialize long-sentence dialogue class
talk.insertModel(readTalkModel()); // Load TF model into long-sentence dialogue class
// Note: The above part is initialization and model loading, executed only once during service startup. Do not load the model every time for recognition!
// TalkToTalk must be a singleton in actual use! The TalkToTalk used for actual getAnswer calls must not be newly created!
// Instead, directly use the singleton class initialized and loaded during service startup. If the model is loaded every time for recognition, the process will be very time-consuming!
String a = talk.getAnswer("Query # student information", 1); // Input question, return answer
System.out.println(a); // Final output: select * from student where id = #
}
public static void init() {
wordEmbedding.setConfig(new SentenceConfig()); // Word embedder sets configuration class
wordEmbedding.setStudyTimes(100); // Word embedder trains for 100 cycles
config.setMaxLength(40); // Set maximum length to 40
config.setMultiNumber(2); // Set 2 multi-heads per encoder/decoder layer
config.setFeatureDimension(wordVectorDimension); // Set word vector dimension
config.setAllDepth(1); // Set TF encoder/decoder depth
config.setSplitWord(" "); // Set space as word delimiter
config.setSelfTimeCode(false); // Set symmetric trigonometric positional encoding
config.setTimes(500); // Train for 500 cycles
config.setStudyPoint(0.01); // Set TF learning rate
config.setShowLog(true); // Print data during training
config.setRegularModel(RZ.NOT_RZ); // No regularization mode
config.setRegular(0.0); // No regularization coefficient
}
public static void study() throws Exception {
SentenceModel sentenceModel = new SentenceModel(config.getSplitWord()); // Set delimiter training sample class
List<TalkBody> talkBodies = data(); // Read test data
for (TalkBody value : talkBodies) { // Insert test data
sentenceModel.setSentence(value.getQuestion()); // Insert question into delimiter-free sample class
sentenceModel.setSentenceBySplitWord(value.getAnswer()); // Insert answer into delimiter sample class
}
wordEmbedding.init(sentenceModel, wordVectorDimension); // Initialize word embedding
WordTwoVectorModel wordTwoVectorModel = wordEmbedding.start(); // Word embedding training completed, return word vector model
talk = new TalkToTalk(wordEmbedding, config); // Create long-sentence dialogue class
talk.init(); // Initialize long-sentence dialogue class
TransFormerModel transFormerModel = talk.study(talkBodies); // Training completed, return TF model
Tools.writeModel(JSONObject.toJSONString(wordTwoVectorModel), "/Users/lidapeng/job/testDocument/model/testWord.json"); // Write model
Tools.writeModel(JSONObject.toJSONString(transFormerModel), "/Users/lidapeng/job/testDocument/model/testTalk.json"); // Write model
}
private static WordTwoVectorModel readWordModel() { // Read model
File file = new File("/Users/lidapeng/job/testDocument/model/testWord.json");
String a = Tools.readPaper(file);
return JSONObject.parseObject(a, WordTwoVectorModel.class);
}
private static TransFormerModel readTalkModel() { // Read model
File file = new File("/Users/lidapeng/job/testDocument/model/testTalk.json");
String a = Tools.readPaper(file);
return JSONObject.parseObject(a, TransFormerModel.class);
}
public static List<TalkBody> data() { // Configure three training data points for testing
List<TalkBody> talkBodies = new ArrayList<>();
TalkBody talkBody1 = new TalkBody();
TalkBody talkBody2 = new TalkBody();
TalkBody talkBody3 = new TalkBody();
talkBody1.setQuestion("Query # student information"); // Query student information where name is #
talkBody1.setAnswer("select * from student where id = #");
talkBody2.setQuestion("Add student information with id # and age 17");
talkBody2.setAnswer("insert into student ( id , age ) values ( # , 17 )");
talkBody3.setQuestion("Change age of # to 18");
talkBody3.setAnswer("update student set age = 18 where id = #");
talkBodies.add(talkBody1);
talkBodies.add(talkBody2);
talkBodies.add(talkBody3);
return talkBodies;
}
}Face Detection Effect Demonstration

Image Recognition FastYolo Effect Demonstration
- Using EasyAi to implement the visual kernel of an image-based automated vending machine

sayOrder AI Customer Service
- sayOrder is an AI customer service system built on EasyAi.
- It can analyze the semantics of user input to identify user behavior and distinguish user intent through typeID. It captures keyword categories set in the backend to extract system-relevant content from user statements, such as time and location.
- It can also autonomously interact with users through Q&A, answering questions or engaging in other intent-based conversations.
- Project link: https://gitee.com/dromara/sayOrder
sayOrder Interaction Basic Workflow Demonstration
- User inputs their idea for the first time:
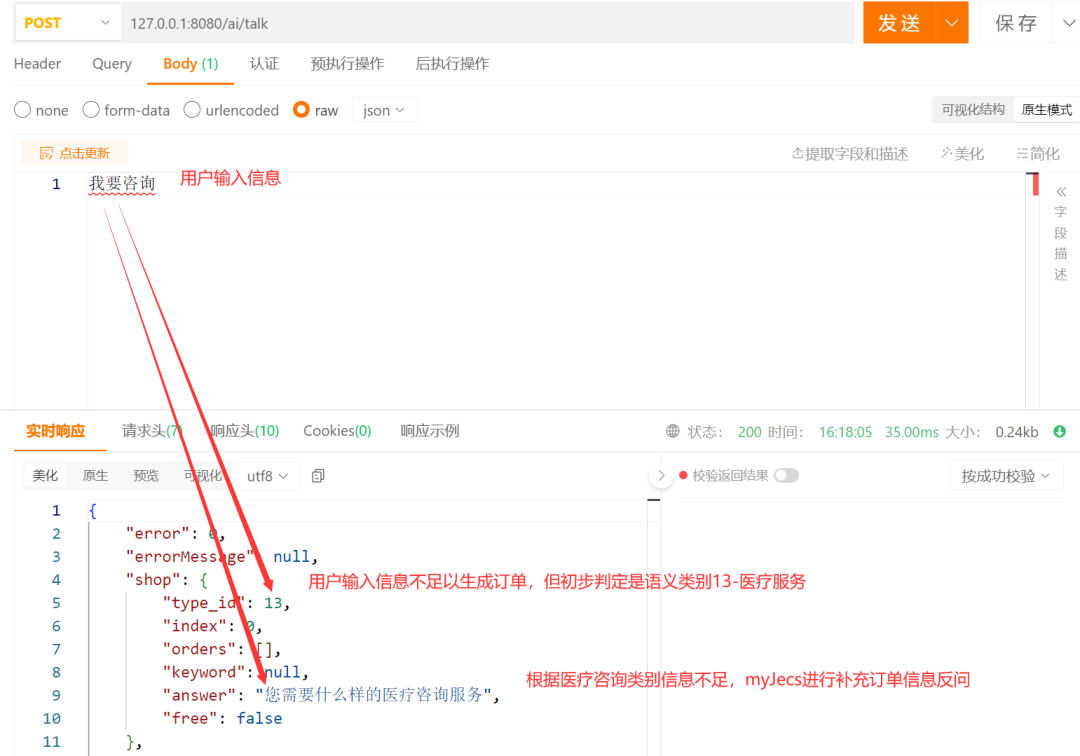
- SayOrder detects missing essential order information and asks a follow-up question. The user responds by providing additional information:
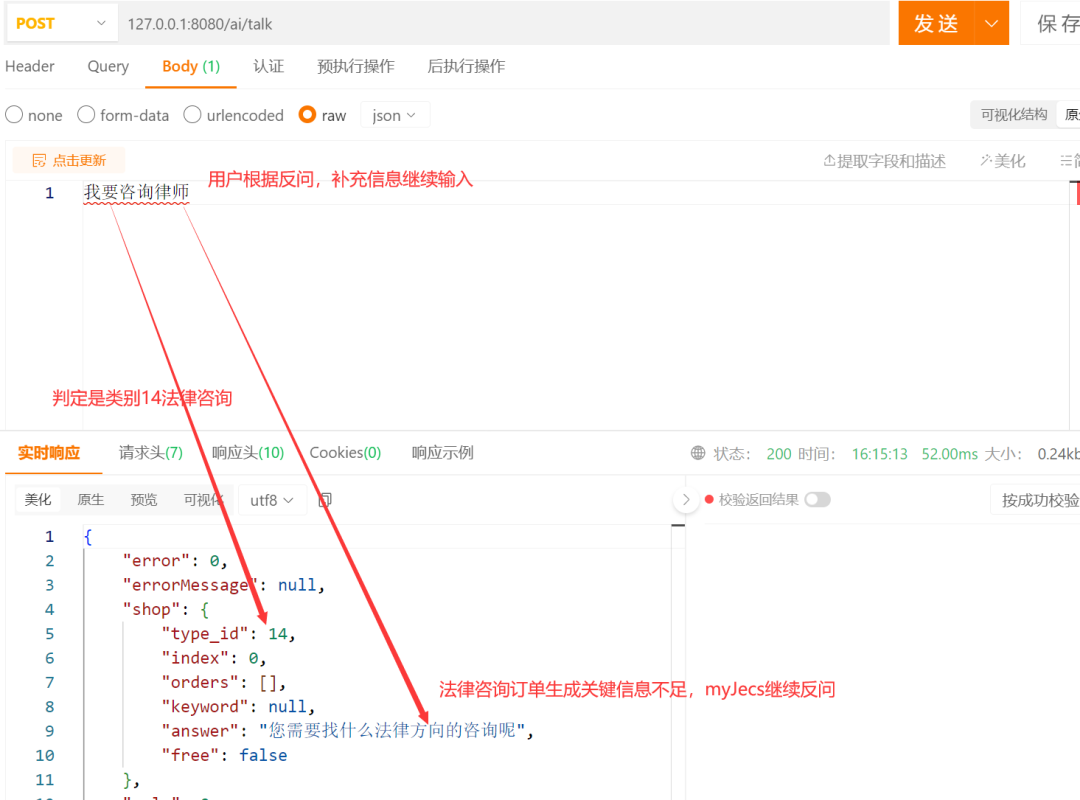
- The user's second input still does not meet the key information requirements for the backend's 14-category legal consultation order. After further supplementation, the order information is completed and the order is generated:
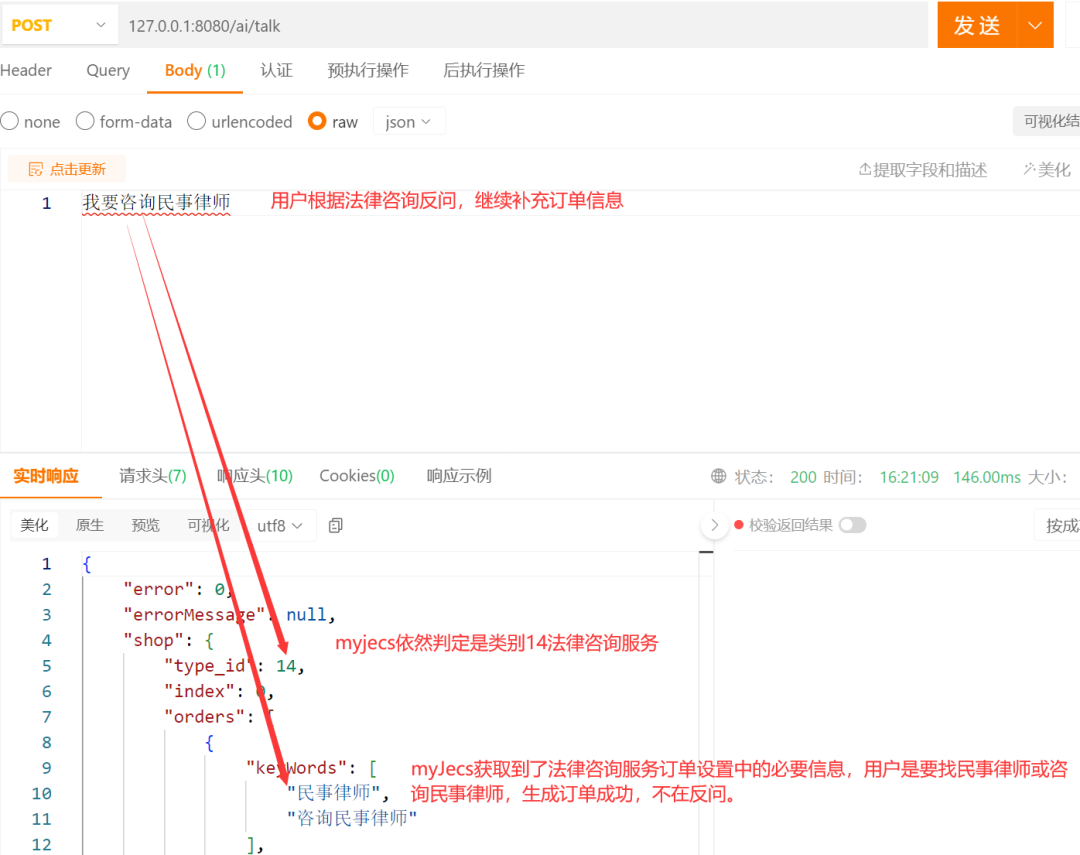
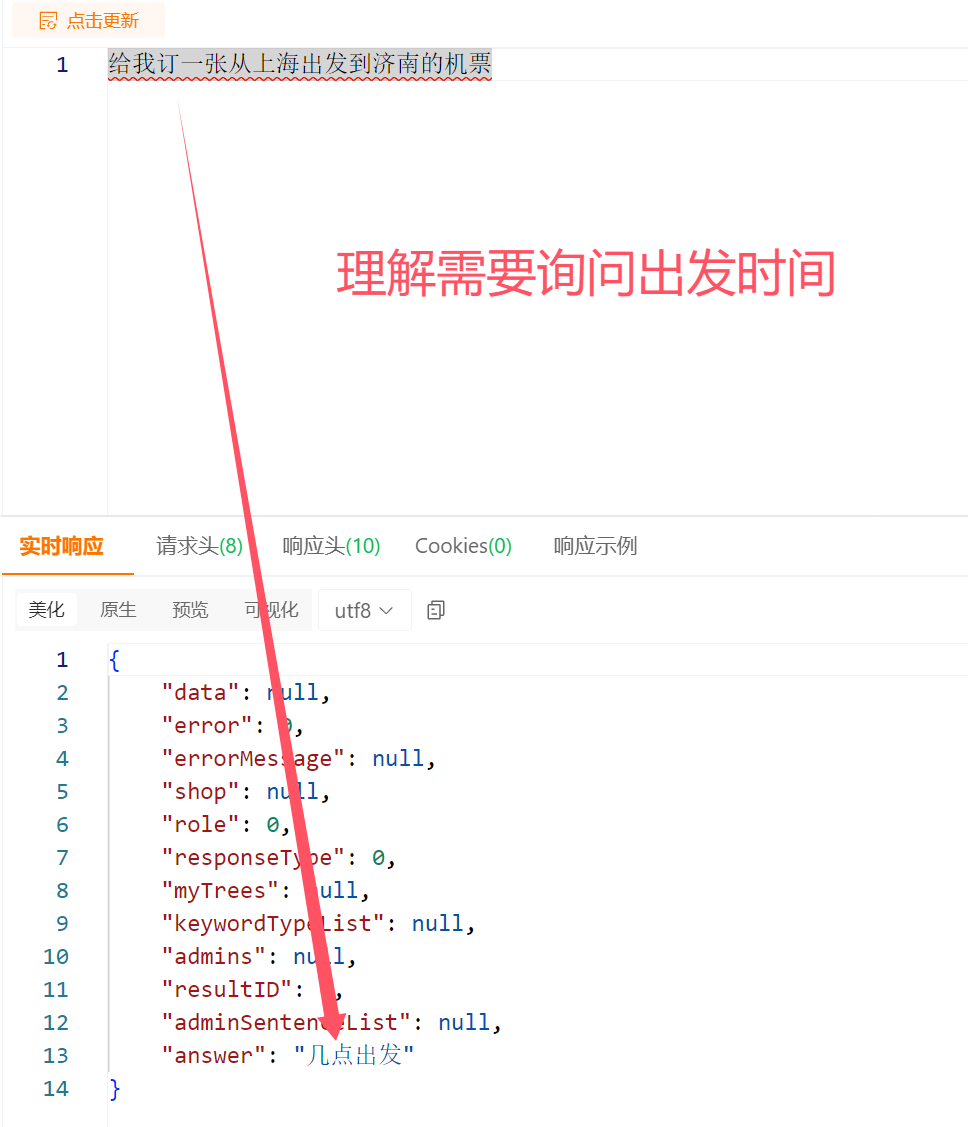
- The user inputs a question they want to consult, and SayOrder autonomously answers the user's query:
Architecture Design
Common Underlying Algorithm Modules
Basic Matrix and Linear Algebra Calculation Module:
- Built-in matrix classes and matrix calculation classes capable of performing common matrix operations, parity checks, multiple linear regression, logistic regression, Euclidean distance, cosine similarity, im2col, inverse im2col, algebraic cofactor calculation, inversion, adjoint matrix calculation, inner product, differentiation, and a series of other APIs.
- RGB three-channel matrices capable of image conversion, cropping, blocking, generating image matrices, and other operations to facilitate subsequent calculations.
Machine Learning - Clustering:
k-means clustering, Gaussian mixture clustering, density clustering, learning vector quantization clustering, etc.Machine Learning - Classification and Fitting:
Multi-layer feedforward neural networks, multi-layer recurrent neural networks, residual networks, multi-layer residual recurrent neural networks, convolutional neural networks, decision trees, random forests, k-nearest neighbors, etc.Heuristic Algorithms:
Particle swarm optimization, ant colony optimization, simulated annealing.Reinforcement Learning:
Dynamic programming, Monte Carlo analysis, Markov decision processes, temporal difference learning.
Common Upper-Level Algorithm Modules
Visual Imaging:
Image recognition, image summarization, target detection.Natural Language Processing:
Semantic understanding, word segmentation, sensitive and keyword inference, sentence completion, language interaction.Game Bots:
Autonomous strategy, autonomous action.
Usage
- Download the project and package it into the local Maven repository.
- Import the EasyAi pom file into the project.
Follow the Project
- For ideas, suggestions, or learning related to the project, you can add my work WeChat:

About Dromara
Dromara is an open-source community composed of top open-source project authors in China. It provides a range of open-source products, solutions, consulting, technical support, and training certification services, including distributed transactions, popular tools, enterprise-level authentication, microservices RPC, operation and maintenance monitoring, Agent monitoring, distributed logs, scheduling orchestration, and more. The technology stack is fully open-source and collaboratively built, maintaining community neutrality, and is dedicated to providing microservices cloud-native solutions for global users. It aims to allow every participating open-source enthusiast to experience the joy of open-source.
The Dromara open-source community currently boasts over 10 GVP (Gitee Most Valuable Project) projects, with a total star count exceeding 100,000. It has built an open-source community of tens of thousands of members, with thousands of individuals and teams using Dromara's open-source projects.
Welcome to join the Knowledge Planet to interact with me
