
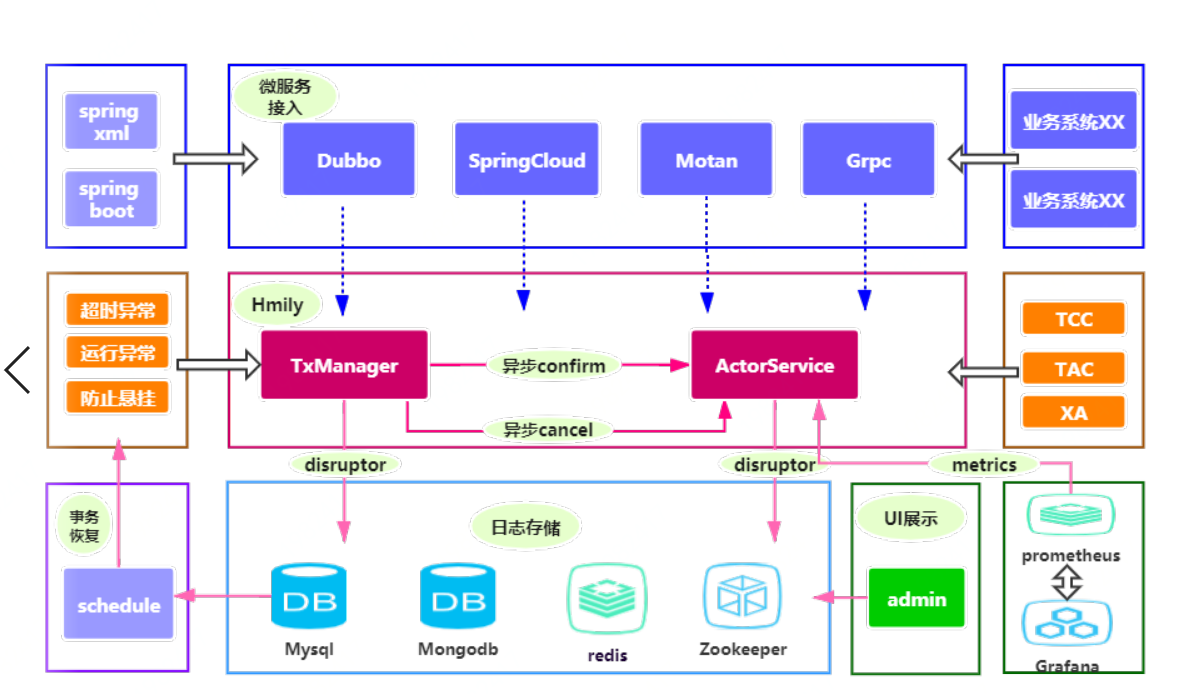
Hmily:Easy Handle Highly Concurrent Distributed Transactions
Handling Highly Concurrent Transactions with Hmily
Let's start with a quick advertisement. Hmily is participating in the Open Source China Annual Popularity Poll at this link. Click the link, search for Hmily, and cast your vote. It's the second one in the 11th row. Thank you, everyone, for your support! Feel free to follow us and submit pull requests to make Hmily even better and more perfect.
GitHub: [https://github.com/yu199195/hmily] Gitee: [https://gitee.com/dromara/hmily]
Now, let's address some questions from the community and clear up some areas of confusion.
1. Performance Issues with Hmily?
Answer: Hmily uses AOP aspect to bind with your RPC methods. It essentially saves logs (using asynchronous disruptor) and passes some parameters when you make an RPC call. Both confirm and cancel operations are now asynchronous, so its performance is similar to that of your RPC. Remember, Hmily doesn't create transactions; it's just a facilitator for distributed transactions. In the past, Hmily had a performance drop due to a locking mechanism in the AOP aspect, as discussed in an article by the Spring Cloud China community. This issue has been resolved now, and everything is asynchronous. The testing scenario was somewhat unreasonable, as it was a demo under default configurations. In the following sections, I'll explain how to improve Hmily's performance.
2. How Does Hmily Handle RPC Call Timeouts?
Answer: In a distributed environment, when you invoke an RPC method and it exceeds the timeout, let's say the Dubbo timeout is set to 100ms but your method takes 140ms, your method has succeeded, but for the caller, it appears as a failure. In this case, a rollback is needed. Hmily's approach is as follows: if the caller thinks the operation failed due to a timeout, it won't include the operation in the rollback chain. So, for an RPC interface that times out, it handles its own rollback. A scheduled task handles the rollback because the log is in the "try" phase, and the cancel method is invoked for rollback, achieving eventual consistency.
3. Hmily's Support for Cluster Deployment and Log Recovery in Cluster Environments?
Answer: Hmily is naturally compatible with cluster deployment as it's bound to your application via AOP aspect. Log recovery in a clustered environment is rarely an issue, unless your entire cluster crashes simultaneously. If your cluster goes down simultaneously and recovers, the logs have a version field; only those that are successfully updated undergo recovery.
4. Hmily Asynchronously Saves Logs, What If a Drastic Event Occurs Before Logging?
Answer: If you're having such thoughts, you probably haven't delved into the source code or didn't fully understand it. In the AOP aspect, logs are first saved asynchronously, with the state being PRE_TRY. After the try phase execution completes, it's updated to "try". Even in scenarios like sudden JVM exit or power loss right after this line of code is executed, the mechanism stands. Even if you're testing scenarios like stopping the JVM abruptly or killing the service, keep in mind that Hmily can't account for all accidental events. It's best not to put excessive effort into solving these rare occurrences; the ideal solution is to not focus on them.
Hmily Configuration Tuning for High-Concurrency Scenarios
The following parameters can be optimized for high-concurrency scenarios in Hmily:
serializer: I recommend using Kryo. Hmily also supports Hessian, Protostuff, and JDK serialization. In our tests, the performance was in the order: Kryo > Hessian > Protostuff > JDK.recoverDelayTime: Delay time for the recovery task (in seconds, default is 120). This parameter should be greater than the timeout set for your RPC calls.retryMax: Maximum retry count (default is 3). When your service goes down, the recovery task will execute your cancel or confirm method for a maximum of retryMax times.bufferSize: Disruptor's buffer size. Increase this for high-concurrency scenarios; it should be a power of 2.consumerThreads: Number of threads for Disruptor's consumer. Increase this for high-concurrency scenarios.started: Set this to true for the initiator side and false for the participant side.asyncThreads: Size of the thread pool for asynchronous execution of confirm and cancel methods. Increase this for high-concurrency scenarios.
Next, the most important aspect: configuring the storage of transaction logs. In our stress tests, I recommend using MongoDB, where the performance ranked as follows: MongoDB > Redis Cluster > MySQL > ZooKeeper.
- If you're using MongoDB for log storage, configure as follows:
<bean id="hmilyTransactionBootstrap" class="com.hmily.tcc.core.bootstrap.HmilyTransactionBootstrap">
<property name="serializer" value="kryo"/>
<property name="recoverDelayTime" value="120"/>
<property name="retryMax" value="3"/>
<property name="loadFactor" value="2"/>
<property name="scheduledDelay" value="120"/>
<property name="scheduledThreadMax" value="4"/>
<property name="bufferSize" value="4096"/>
<property name="consumerThreads" value="32"/>
<property name="started" value="false"/>
<property name="asyncThreads" value="32"/>
<property name="repositorySupport" value="db"/>
<property name="tccDbConfig">
<bean class="com.hmily.tcc.common.config.TccDbConfig">
<property name="url"
value="jdbc:mysql://192.168.1.98:3306/tcc?useUnicode=true&characterEncoding=utf8"/>
<property name="driverClassName" value="com.mysql.jdbc.Driver"/>
<property name="username" value="root"/>
<property name="password" value="123456"/>
</bean>
</property>
</bean>Here, I recommend using Kryo. Of course, Hmily also supports Hessian, Protostuff, and JDK serialization. In our tests, the performance was in the order: Kryo > Hessian > Protostuff > JDK.
recoverDelayTime :Delay time for the recovery task (in seconds, default is 120). This parameter should be greater than the timeout set for your RPC calls.
retryMax : Maximum retry count (default is 3). When your service goes down, the recovery task will execute your cancel or confirm method for a maximum of retryMax times.
Disruptor's buffer size. Increase this for high-concurrency scenarios; it should be a power of 2.
consumerThreads: Disruptor's consumer thread count. Increase this for high-concurrency scenarios.
started: Set this to true for the initiator side and false for the participant side.
asyncThreads: Size of the thread pool for asynchronous execution of confirm and cancel methods. Increase this for high-concurrency scenarios.
Next is the most important aspect: configuring the storage of transaction logs. In our stress tests, I recommend using MongoDB, where the performance ranked as follows: MongoDB > Redis Cluster > MySQL > ZooKeeper.
If you're using MongoDB for log storage, configure as follows:
<property name="repositorySupport" value="mongodb"/>
<property name="tccMongoConfig">
<bean class="com.hmily.tcc.common.config.TccMongoConfig">
<property name="mongoDbUrl" value="192.168.1.68:27017"/>
<property name="mongoDbName" value="happylife"/>
<property name="mongoUserName" value="xiaoyu"/>
<property name="mongoUserPwd" value="123456"/>
</bean>
</property>If you're using Redis for log storage, configure as follows:
- Single node Redis:
<property name="repositorySupport" value="redis" />
<property name="tccRedisConfig">
<bean class="com.hmily.tcc.common.config.TccRedisConfig">
<property name="hostName"
value="192.168.1.68"/>
<property name="port" value="6379"/>
<property name="password" value=""/>
</bean>
</property>- Redis sentinel mode cluster:
<property name="repositorySupport" value="redis"/>
<property name="tccRedisConfig">
<bean class="com.hmily.tcc.common.config.TccRedisConfig">
<property name="masterName" value="aaa"/>
<property name="sentinel" value="true"/>
<property name="sentinelUrl" value="192.168.1.91:26379;192.168.1.92:26379;192.168.1.93:26379"/>
<property name="password" value="123456"/>
</bean>
</property>- Redis cluster mode:
<property name="repositorySupport" value="redis"/>
<property name="tccRedisConfig">
<bean class="com.hmily.tcc.common.config.TccRedisConfig">
<property name="cluster" value="true"/>
<property name="clusterUrl" value="192.168.1.91:26379;192.168.1.92:26379;192.168.1.93:26379"/>
<property name="password" value="123456"/>
</bean>
</property>- If you're using ZooKeeper for log storage, configure as follows:
<property name="repositorySupport" value="zookeeper"/>
<property name="tccZookeeperConfig">
<bean class="om.hmily.tcc.common.config.TccZookeeperConfig">
<property name="host" value="192.168.1.73:2181"/>
<property name="sessionTimeOut" value="100000"/>
<property name="rootPath" value="/tcc"/>
</bean>
</property>- The database configuration has been provided above, and I won't introduce the file-based storage approach.
- The above is the content shared today, an annotation, and a few configuration lines to easily handle high-concurrency distributed transactions!